
- A Survey on Offline Reinforcement Learning Taxonomy, Review, and Open Problems
0. Contributions
-
- 分类法:提出了一种新的离线强化学习方法分类方法。方法可以属于不同的类别,包括基于模型的学习方法、一步学习方法和模仿学习方法。此外,方法可以对其损失进行若干修改,包括策略约束、正则化或不确定性估计项。
-
- 算法评估:使用统一的符号提供离线强化学习方法的最新文献综述,包括对开创性作品,最近发表的文章和有前途的预印本的详细讨论。
-
- 数据集评估:评估了目前文献中可用的基准,并讨论了它们的数据集如何满足离线RL数据集的一些关键特性。这使得研究人员可以了解在哪里评估他们的方法,以评估其解决特定问题的能力,例如,应该使用哪个数据集来确定他们的方法是否能很好地处理次优数据。此外,它将允许人们根据数据集属性对数据集进行分类,并了解常见的陷阱。
-
- 方法性能:提供了一个图表,显示了每个方法和方法类在我们定义的每个数据集属性上的相对性能。这将为研究人员提供工具,为给定问题选择最佳算法,并确定具有最有前途性能的算法类别。
-
- 开放性问题:讨论了我们对该领域的一些开放问题的看法,包括非策略评估(OPE)方法,可靠的离线RL工作流以及动态调节算法保守程度的能力。
1. Introduction
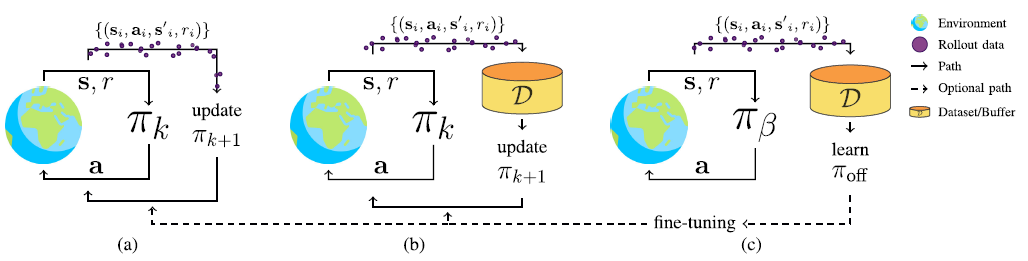
Fig.1. Illustration of the different RL paradigms, including (a) online RL, (b) off-policy RL, and (c) offline RL. In online RL new experiences must be collected with the latest policy before making an update. In off-policy RL, we reuse previous experiences but still rely on a continuous collection of new experiences. In contrast, offline RL only uses previous experiences collected with a behavior policy $\pi_\beta$ and stored in a static dataset D to learn a policy $\pi_{off}$. After learning $\pi_{off}$, one can opt to fine-tune it using online or off-policy RL methods. This image is largely based on Levine et al.’s [8] pictorial illustration of RL paradigms. Earth image made by Freepik from www.flaticon.com. cite by paper.
2. Background
简要介绍了在线和离线强化学习的背景,介绍了这些方法背后的符号和关键概念。
2.1. Markov Decision Process (MDP)
2.2. Reinforcement Learning
finding an optimal policy $\pi^{*}_{(a|s)}$ that maximizes the expected return for all trajectories induced by the policy, such that \(\pi^{*} = argmax \ \mathbb{E}_{\tau \sim p_{\pi}(\cdot)} [R_{0:H}]\)
Policy gradients are one of the key RL methods that directly maximize this objective to find $\pi^{*}$。
Methods like policy iteration and value iteration rely on different quantities of interest to find an optimal policy $\pi^{*}$, such as state-value and action-value functions, and advantage funcitons.
a) State-value function for a policy $\pi$: \(V^{\pi}(s_{t}) \.= \mathbb{E}_{\tau \sim p_{\pi}(\cdot|s_{t})} [R_{t}]\)
b) Action-value function for a policy $\pi$: \(Q^{\pi}(s_{t}, a_{t}) \.=\)
c) Advantage function \(A^{\pi}(s_{t}, a_{t}) \.=\) it represents how advantageous it is to take action $a_{t}$ as compared with the average performance we would expect from state $s_{t}$.
Dynamic programming 动态规划起源于最优控制,可用于基于已知MDP计算最优策略。
Model free 在无模型方法中,我们假设我们不知道MDP,而只需要从它的样本中学习。
- (Policy-based) Policy gradients that directly learn a policy.
- (Value-based) Value iteration methods that learn a value function used to extract a policy.
- (Policy value both) Actor–critic methods that learn both quantities by iteratively alternating between policy evaluation and policy improvement
Model based 尝试学习 MDP 的模型,然后可以将其用于规划或通过从 MDP 中采样并使用无模型方法进行训练来学习策略.
2.3. Offline Reinforcement Learning
交互式学习范式的根本问题是,每次我们改变策略时,我们都需要重新收集整个数据集,这在现实世界中是非常昂贵的。RL广泛使用模拟训练的主要原因之一是为了避免与现实环境交互的成本和危险。
在离线强化学习设置中,我们有一个由未知行为策略 $\pi_{\beta}$收集的固定数据集,然后使用该数据集来学习新的和改进的策略 $\pi_{off}$,而不与环境进一步交互。
In the offline RL setting, we are given a static dataset of transitions $D={(s_{t}, a_{t}, s_{t+1}, r_{t}) }$ where i indexes a transition in the dataset, the actions come from the behavior policy $a_{t} \sim \pi_{\beta}(\cdot s_{t})$, the states come from a distribution induced by the behavior policy $s_{t} \sim d^{\pi_{\beta}} (\cdot)$, the next state is determined by the transition dynamics $a_{t=1} \sim T(\cdot s_{t}, a_{t})$, and the reward is a function of state and action $r_{t} = r(s_{t}, a_{t})$.
| 在离线强化学习设置中,我们得到一个静态转换数据集 $D={(s_{t}, a_{t}, s_{t+1}, r_{t}) }$, 其中, 第i索引在数据集中的一个转换,动作来自行为策略 $a_{t} \sim \pi_{\beta}(\cdot | s_{t})$, 状态来自行为策略 $s_{t} \sim d^{\pi_{\beta}} (\cdot)$,下一个状态由过渡动态决定 $a_{t=1} \sim T(\cdot | s_{t}, a_{t})$, 奖励函数 $r_{t} = r(s_{t}, a_{t})$. |
在离线强化学习中,目标仍然与在线案例相同: 找到一个最大化预期回报的策略。
3. Taxonomy
在图2中,展示了离线RL分类。
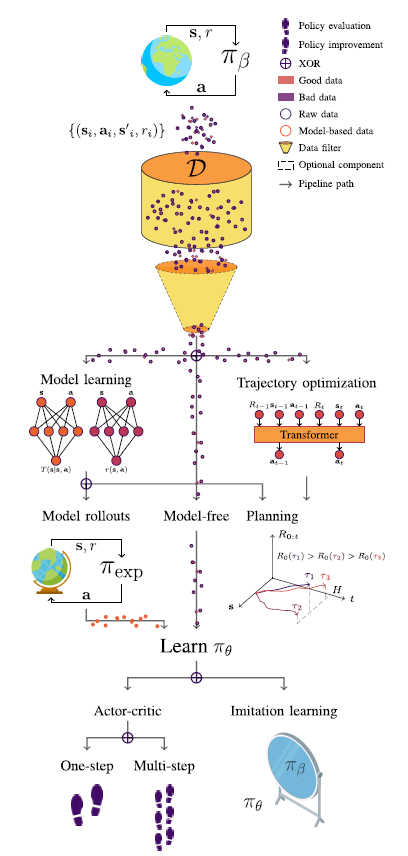

4. Algorithmic review
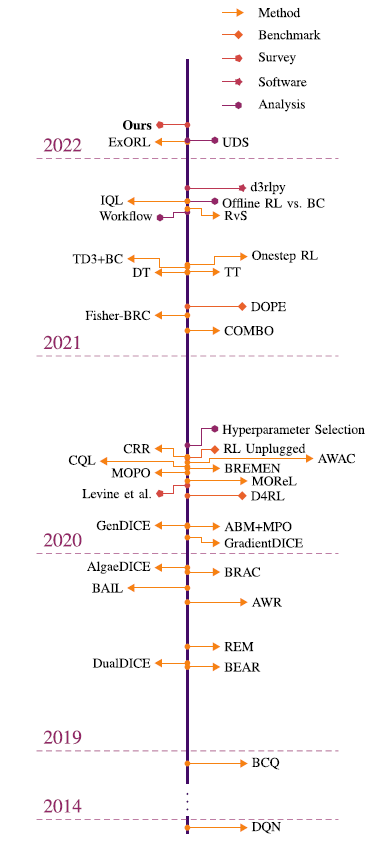
Fig. 时间表按顺序和时间间隔展示了从 2018 年底至今(2022 年)离线强化学习领域的主要发展。 该时间表包括该领域发表的方法、基准、调查、软件和分析论文。 在时间线的开始,重点介绍 DQN,这是一种离线策略(off-policy) RL 方法,它提出了一种能够从像素观察中学习如何玩多个 Atari 游戏的代理,并开创了深度 RL 领域。 然后我们跳到 2018 年底,重点介绍 BCQ,这是离线 RL 领域的开创性工作之一,正式介绍了它的一些挑战(例如,分布转移)。 时间线中显示的日期是预印本的提交日期,可通过单击每个事件进行访问。
4.1. Policy Constraints
解决离线训练数据与在线数据的分布偏移问题 (distributional shift problem)
4.1.1 Direct
-
BCQ:
直接策略约束 $\pi_{\theta}$ 靠近 $\pi_{\beta}$,
S. Fujimoto, D. Meger, and D. Precup, “Off-policy deep reinforcement learning without exploration,” in ICML, 2019, pp. 2052–2062.
-
BRAC:
行为规格化行为者批评(bootstrapping error accumulation reduction, BRAC),行为规格化行为者批评方法的一般框架。BRAC允许人们通过从两个目标中减去一个分歧项来惩罚政策改进或政策评估步骤。
总的来说,他们发现应用价值惩罚比规范化策略更有利,他们使用 BRAC-v 和 BRAC-p 取得了最佳结果,它们使用 $D_{KL}(\pi_{\theta}| \pi_{\beta} )$ 作为 $f$ 散度来约束策略 分别为政策评估步骤和政策改进步骤。 由于 BRAC 依赖于 $\pi_{\beta}$ 的最大对数似然估计,因此它被认为是直接策略约束方法。
- BRAC-p
Y. Wu, G. Tucker, and O. Nachum, “Behavior regularized offline reinforcement learning,” 2019, arXiv:1911.11361.
- BRAC-p
-
Fisher-BRC (Fisher-behavior regularized critic)
Uses a Fisher divergence $D_{F}(\pi_{\theta}| \pi_{\beta} )$ to constrain the entropy-regularized learned policy.
4.1.2 Implicit
- BEAR
A. Kumar, J. Fu, M. Soh, G. Tucker, and S. Levine, “Stabilizing offpolicy Q-learning via bootstrapping error reduction,” in Proc. NeurIPS, 2019, pp. 1–11.
-
BRAC-v
-
AWR (advantage-weighted regression) 该算法在策略改进步骤中隐式地应用了KL散度约束。
- AWAC (advantageweighted actor–critic)使用一个估计q函数的优势,以减少其方差和提高样本效率。
4.2 Importance Sampling
4.3 Regularization
通过设计添加策略正则项解决数据分布偏移问题
- Regarding policy regularization
- SACs (soft actor–critics)
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Offpolicy maximum entropy deep reinforcement learning with a stochastic actor,” in Proc. ICML, vol. 80, Jul. 2018, pp. 1861–1870.
- SACs (soft actor–critics)
- Regarding value regularization
- CQL (constrained Q-learning)
A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative Q-learning for offline reinforcement learning,” in Proc. NeurIPS, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020, pp. 1179–1191.
- CQL (constrained Q-learning)
4.4 Uncertainty Estimation
估计不确定性的一种方法是用集合Q-functions。
4.5 Model-Based Methods
4.6 One-Step Methods
4.7 Imitation Learning
4.8 Trajectory Optimization
6. Benchmark review
6.1 Offline RL Benchmarks
6.1.1 数据集设计因素
-
离线数据集的属性必须能够提供有意义的衡量标准,以推动离线强化学习的实际应用取得进展。为离线强化学习的实际应用进展提供有意义的衡量标准。 这些属性包括:
Datasets Overview:
给出了迄今为止最大的两个离线RL基准测试:D4RL 和 RL Unplugged,概述了每个基准测试中的环境及其满足的属性。
- D4RL
D4RL基准测试包括OpenAI的Gym-MuJoCo任务、迷宫、灵巧操作任务(即Adroit)、机器人操作任务(即frankakkitchen)、自动驾驶(即汽车学习行为(CARLA))和交通模拟(即流量)的数据集。
J. Fu, A. Kumar, O. Nachum, G. Tucker, and S. Levine, “D4RL: Datasets for deep data-driven reinforcement learning,” 2020, arXiv:2004.07219.
- RL Unplugged
RL Unplugged基准测试由来自四个不同套件的数据集组成,包括DeepMind控制 Suite, DeepMind运动,街机学习环境(ALE)和现实世界的RL套件。
C. Gulcehre et al., “RL unplugged: A suite of benchmarks for offline reinforcement learning,” in Proc. Adv. Neural Inf. Process. Syst., 2021, pp. 7248–7259.
当前离线RL基准测试中缺少的一些属性。