
2021-2022年浏览论文
109. A Projective Geometric View for 6D Pose Estimation in mmWave MIMO Systems
- 阅读时间: 2023-2-13
- 出处: Digital Signal Processing
- 关键词: AoD, AoA, pose estimation, SLAM, antenna arrays, mmWave communication
- 摘要: 30–300 GHz 频段的毫米波 (mmWave) 系统是 5G 和超 5G 的基础使能技术之一,提供大带宽,不仅适用于高数据速率通信,还适用于精确定位服务,支持高 精度要求高的应用,如车辆定位。 由于可以在占用空间较小的用户设备上引入相对较大的阵列,因此可以解锁确定用户方向的能力。 完整用户姿势(联合 3D 位置和 3D 方向)的估计称为 6D 定位。 传统上,使用天线阵列的 6D 定位问题被认为是困难的,并通过启发式和优化的组合来解决。 在本文中,我们揭示了 AoA 和 AoD 与计算机视觉中经过充分研究的透视投影模型之间的密切联系。 这种联系使我们能够通过采用计算机视觉中最先进的方法来解决 6D 定位问题。 更具体地说,两个问题,即来自多个单天线基站的 AoA 的 6D 姿态估计和基于单 BS 毫米波通信的 6D SLAM,首先用透视投影模型建模,然后求解。 数值模拟表明,所提出的估计器的运行接近理论性能界限。 此外,即使在没有 LoS 路径或不知道 LoS/NLoS 条件的情况下,所提出的 SLAM 方法也是有效的。
108. A novel beamforming technique using mmWave antenna arrays for 5G wireless communication networks
- 阅读时间: 2023-2-13
- 出处: Digital Signal Processing
- 关键词: 波束形成,毫米波天线阵列, 天线设计, 5G, 旁瓣电平降低
- 摘要: 毫米波 (mmWave) 多输入多输出 (MIMO) 和波束成形技术很可能是 5G 及更高版本 (5G-B) 无线通信系统的组成部分和关键推动因素。 从这个角度来看,这份手稿提出了一种适用于 5G 应用的高效数字波束成形技术。 建议的方法是基于可靠的采样技术制定的,该技术可以有效地对干扰加噪声协方差矩阵 (IPNCM) 进行采样以构建有效的投影矩阵 (PM)。 因此,所提出的技术被命名为干扰加噪声 PM (IPNPM) 波束形成器。 接下来,使用 CST 微波工作室设计了一个紧凑型矩形微带天线,其工作频率为 49.3 GHz,潜在带宽为 1.7 GHz。 设计的天线随后用于模拟代表典型 5G 基站的 32 元均匀线性阵列 (ULA)。 然后,建模的 ULA 的元素被手动输入从建议的波束形成器生成的复数权重,以分别向所需和不需要的位置产生高功率波束和深度空值。 为了进一步提高波束形成器在最小化不需要区域内的辐射功率方面的性能,开发了迭代旁瓣电平 (SLL) 抑制技术并将其与所提出的波束形成器集成。 进行的理论分析证明,IPNPM 波束形成器比众所周知的波束形成方法需要更少的算术运算。 为了揭示所提出技术的优势,绘制了基于所提出波束形成器的阵列辐射方向图,并将其与三种广泛使用的方法的辐射方向图进行了比较。 还进行了密集的蒙特卡罗模拟,其中系统地将 IPNPM 波束形成器性能与基于输出信号与干扰加噪声比 (SINR) 标准的流行方法进行了比较。 取得的结果表明,所提出的方法在生成更深的空值、增强的输出 SINR 和更短的执行时间方面优于并超越了竞争对手的算法。 还表明,与现有的 SLL 减少技术不同,新开发的 SLL 抑制器在几次迭代后将所提出的波束形成器的 SLL 减少到预定义的阈值(即 -24 dB)。
3. Fast Wideband Beamforming Using Convolutional Neural Network
- 阅读时间: 2023-2-13
- 出处: 《remote sensing》 开源SCI,IF4.509,JCR一区、中科院二区。
- 关键词: 阵列天线雷达; 自适应宽带波束形成; 卷积神经网络; 预测网络; 计算复杂度低
- 摘要: 通过宽带波束形成方法,合成孔径雷达(SAR)可以实现高方位分辨率和宽测绘带。 然而,传统的自适应宽带时域波束成形的性能受到严重影响,因为接收到的信号快照不足以用于自适应方法。 在本文中,提出了一种使用卷积神经网络(CNN)方法的宽带波束形成器,即频率约束宽带波束形成预测网络(WBPNet),以获得在少量快照的情况下令人满意的性能。 所提出的 WBPNet 通过利用 CNN 的独特性提取输入信息的潜在非线性特征,成功地估计了少量快照干扰的到达方向,并获得了对干扰有效为零的最佳权重。 同时,新型波束形成器对感兴趣的宽带信号具有无失真响应。 与传统的时域宽带波束形成算法相比,该方法由于使用的快照较少,可以快速获得自适应权重。 此外,所提出的 WBPNet 在宽带波束形成方面具有令人满意的性能,计算复杂度低,因为它避免了协方差矩阵的逆运算。 仿真结果表明了该方法的优越性和可行性。
107. Through-Wall Human Mesh Recovery Using Radio Signals
- 阅读时间: 2022-10-7
- 出处: ICCV2019
- 关键词: 射频信号估计人体Mesh
-
摘要: 本文介绍了RF-Avatar,一种神经网络模型,可以在闭塞、宽松的衣服和糟糕的光照条件下估计人体的3D网格。我们利用WiFi范围内的射频(RF)信号穿过衣服和遮挡物,并从人体反弹回来。我们的模型解析这样的无线电信号,并恢复三维身体网格。我们的网格是动态的,可以平滑地跟踪相应人员的移动。此外,我们的模型适用于单人和多人的场景。从无线电信号推断物体网格是一个高度不受约束的问题。我们的模型使用以下方法来应对这一挑战:1)强监督和弱监督的组合,2)一个多头自我注意机制,它对无线电信号中的时间信息进行不同的关注,3)一个对抗式训练的时间鉴别器,它对人类运动的动力学施加了先验。我们的结果表明,在闭塞、宽松的衣服、糟糕的光照条件,甚至穿过墙壁的情况下,RF-Avatar可以准确地恢复动态3D网格。
- 应用场景: </br>
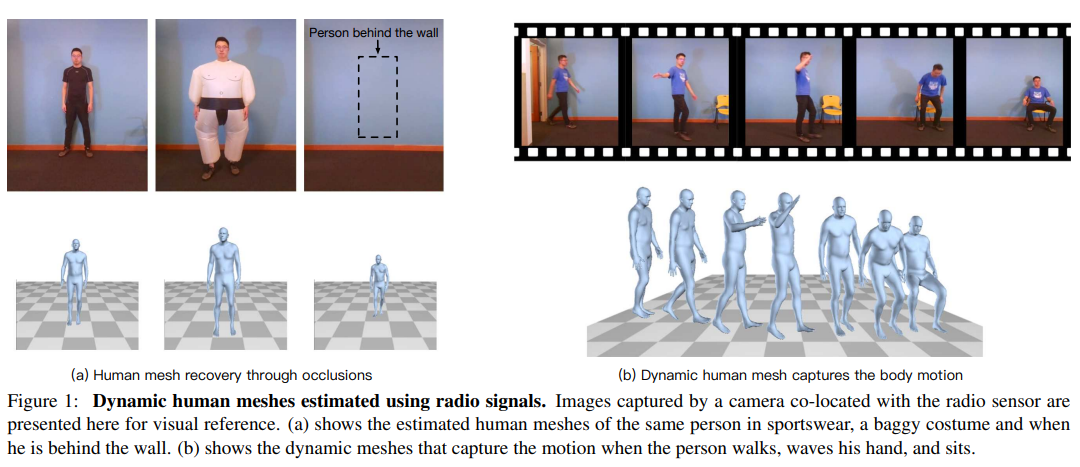
-
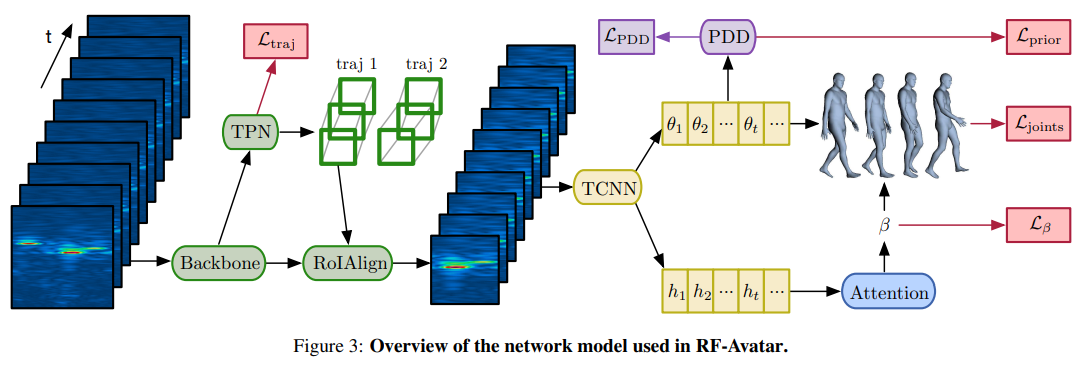
系统框架: Overview of the network model used in RF-Avatar,收到Mask-RCNN启发,利用4D-RF信号特征生成3D body Mesh
106. Image-to-Image Translation with Conditional Adversarial Networks
- 阅读时间: 2022-10-7
- 出处: CVPR2017
- 关键词: 图像生成图像网络
-
摘要: 我们研究条件对抗网络作为图像到图像转换问题的通用解决方案。 这些网络不仅学习从输入图像到输出图像的映射,而且学习损失函数来训练这个映射。 这使得将相同的通用方法应用于传统上需要非常不同的损失公式的问题成为可能。 我们证明了这种方法在从标签地图合成照片、从边缘地图重建对象和为图像着色等任务中是有效的。 事实上,自与本文相关的 pix2pix 软件发布以来,大量互联网用户(其中许多是艺术家)发布了他们自己对我们系统的实验,进一步证明了其广泛的适用性和易于采用而无需调整参数 . 作为一个社区,我们不再手动设计我们的映射函数,这项工作表明我们也可以在不手动设计损失函数的情况下获得合理的结果。
- 应用场景: </br> 图像处理、图形和视觉中的许多问题都涉及将输入图像转换为相应的输出图像。 这些问题通常使用特定于应用程序的算法来处理,即使设置始终相同:将像素映射到像素。 条件对抗网络是一种通用解决方案,似乎可以很好地解决这些问题中的各种问题。 在这里,我们展示了该方法在几个方面的结果。 在每种情况下,我们都使用相同的架构和目标,并简单地训练不同的数据。
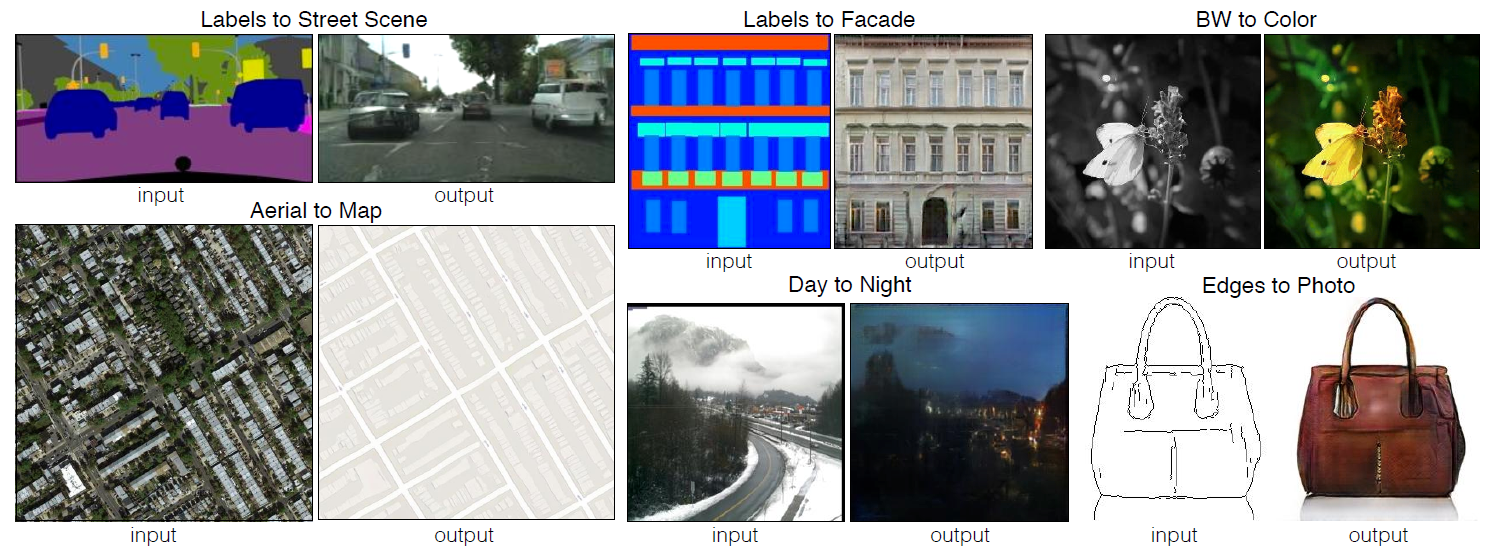
- 动机: 建立图像到图像的映射关系
105. MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review(A Review)
- 摘要: 随着自动驾驶发展进入蓬勃发展阶段,复杂场景下的精确物体检测受到广泛关注,以确保自动驾驶的安全性。毫米波 (mmWave) 雷达和视觉融合是精确障碍物检测的主流解决方案。本文详细介绍了基于毫米波雷达和视觉融合的障碍物检测方法。首先,我们介绍了自动驾驶目标检测的任务、评估标准和数据集。然后,毫米波雷达与视觉融合的过程分为传感器部署、传感器标定和传感器融合三个部分,综合回顾。特别是,我们将融合方法分为数据级、决策级和特征级融合方法。此外,我们在障碍物检测、物体分类和道路分割等方面介绍了自动驾驶中激光雷达和视觉的融合,这在未来很有前景。
104. Millimeter Wave Sensing: A Review of Application Pipelines and Building Blocks(IEEE Sensors Journal: Review)
- 摘要: 新无线应用对带宽的需求不断增加,导致了用于高速无线通信的毫米波频谱的标准化。毫米波频谱是 5G 的一部分,涵盖 30 至 300 GHz 之间的频率,对应于 10 至 1 毫米的波长。尽管毫米波通常被认为是一种通信介质,但由于其窄波束、宽带宽操作以及与大气成分的相互作用,它也被证明是一种出色的“传感器”。在本文中,据我们所知,这是第一篇完全涵盖毫米波传感应用管道的综述,我们对不同的基本应用管道构建块进行了全面的概述和分析,包括硬件、算法、分析模型和模型评估技术。该评论还提供了一个分类法,重点介绍了不同的毫米波传感应用领域。通过深入分析,遵循系统文献综述方法,查阅 165 篇论文,我们不仅扩展了以往仅专注于毫米波技术通信方面和使用毫米波技术进行主动成像的研究,而且突出了科学和技术挑战和趋势,并为毫米波作为传感技术的应用提供未来前景。
103. Big Brother is Listening: An Evaluation Framework on Ultrasonic Microphone Jammers
-
InfoCom2022
-
摘要: 通过麦克风进行的秘密窃听一直是对用户隐私的主要威胁。得益于声学非线性特性,超声波麦克风干扰器 (UMJ) 可有效抵抗这种长期存在的攻击。然而,先前的 UMJ 研究低估了对手在现实中的攻击能力,并错过了进行全面评估的关键指标。对手在低单词识别率下无法检索信息的强假设,以及对手在威胁模型中的弱去噪能力使得这些工作忽略了现有 UMJ 的脆弱性。因此,他们的 UMJ 的弹性被高估了。在本文中,我们改进了对手模型并全面调查了潜在的窃听威胁。相应地,我们总共定义了 12 个评估 UMJ 弹性所必需的指标。使用这些指标,我们提出了一个全面的框架来量化 UMJ 的实际弹性。它完全涵盖了先前工作在一定程度上忽略的三个视角,即环境信息、语义理解和协作识别。在这个框架的指导下,我们可以彻底和定量地评估现有 UMJ 对窃听者的弹性。我们广泛的评估结果表明,大多数现有的 UMJ 都容易受到复杂的不利方法的影响。我们进一步概述了影响干扰器性能的关键因素,并为 UMJ 的未来设计提出了建设性的建议。
102. mmPhone: Acoustic Eavesdropping on Loudspeakers via mmWave-characterized Piezoelectric Effect
-
INFOCOM 2022
-
摘要: 摘要——越来越多的人转向使用带有扬声器的设备进行在线语音通信,因为它很方便。为防止语音泄漏,通常采用隔音室。本文介绍了 mmPhone,这是一种新型声学窃听系统,可恢复受隔音环境保护的扬声器语音。关键思想是,毫米波波段的压电薄膜的性质会因压电效应而随声压而变化。如果对手获得了属性变化(即,用毫米波表征压电效应),则可能发生语音泄漏。更重要的是,压电薄膜可以在没有电源的情况下工作。基于此,我们提出了一种使用 mmWaves 的方法感知电影并解码来自毫米波的语音,从而将电影变成一个被动的“麦克风”。为了恢复可理解的语音,我们进一步开发了一种基于去噪神经网络、多通道增强和语音合成的增强方案,以补偿毫米波的传播和穿透损失。我们进行了广泛的实验来评估 mmPhone 并以超过 93% 的准确率进行数字识别。结果表明,mmPhone 可以从超过 5m 的距离恢复高质量和可理解的语音,并且对声波的入射角(55 度以内)和不同类型的扬声器具有弹性。
99. Enhancing Audio-Visual Association with Self-Supervised Curriculum Learning
-
摘要: 视听表示学习最近的成功很大程度上归功于它们普遍的并发特性,可以用作自我监督信号并提取相关信息。虽然最近的工作重点是捕捉音频和视觉模态之间的共享关联,但他们很少同时考虑多个音频和视频对,也很少注意利用每个模态中的有价值信息。为了解决这个问题,我们提出了一种新的视听表示学习方法,称为师生学习方式下的自我监督课程学习(SSCL)。具体来说,利用对比学习,利用了两阶段方案,将教师和学生模型之间的跨模态信息作为一个分阶段的过程传输。所提出的 SSCL 方法将视听并发的普遍属性视为潜在监督,并将视听数据的结构知识相互提炼。值得注意的是,SSCL 方法可以为各种下游应用学习有区别的音频和视觉表示。在动作视频识别和音频声音识别任务上进行的大量实验表明,与最先进的自监督视听表示学习方法相比,SSCL 方法的性能显着提高。
-
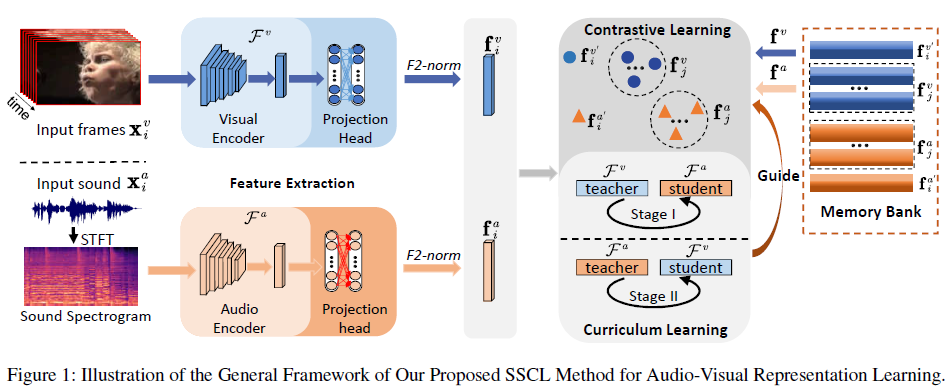
98. End-To-End Audio-Visual Speech Recognition with Conformers
-
具有一致性的端到端视听语音识别
-
摘要: 在这项工作中,我们提出了一个基于 ResNet-18 和卷积增强转换器 (Conformer) 的混合 CTC/Attention 模型,可以以端到端的方式进行训练。特别是,音频和视觉编码器分别学习直接从原始像素和音频波形中提取特征,然后将其馈送到构象器,然后通过多层感知器 (MLP) 进行融合。该模型结合使用 CTC 和注意力机制来学习识别字符。我们展示了端到端训练,而不是使用文献中常见的预先计算的视觉特征,使用conformer,而不是循环网络,以及使用基于transformer的语言模型,显着提高了我们模型的性能。我们分别在最大的公开可用的句子级语音识别数据集、Lip Reading Sentences 2 (LRS2) 和 Lip Reading Sentences 3 (LRS3) 上展示了结果。结果表明,我们提出的模型在纯音频、纯视觉和视听实验中大幅提高了最先进的性能。
-
-Reference :
@inproceedings{DBLP:conf/icassp/0001PP21a, author = {Pingchuan Ma and Stavros Petridis and Maja Pantic}, title = {End-To-End Audio-Visual Speech Recognition with Conformers}, booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing, {ICASSP} 2021, Toronto, ON, Canada, June 6-11, 2021}, pages = {7613--7617}, publisher = , year = {2021}, url = {https://doi.org/10.1109/ICASSP39728.2021.9414567}, doi = {10.1109/ICASSP39728.2021.9414567}, timestamp = {Fri, 09 Jul 2021 13:04:25 +0200}, biburl = {https://dblp.org/rec/conf/icassp/0001PP21a.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
97. A Closer Look at Audio-Visual Multi-Person Speech Recognition and Active Speaker Selection
-
仔细研究视听多人语音识别和主动说话者选择
-
摘要: 视听自动语音识别是在嘈杂条件下实现鲁棒 ASR 的一种很有前途的方法。然而,直到最近,它一直是孤立地研究的,假设单个说话人脸的视频与音频相匹配,并且在多个人在屏幕上的推理时间选择活跃的说话者被作为一个单独的问题搁置一旁。作为替代方案,最近的工作提出用注意力机制同时解决这两个问题,将说话人选择问题直接烘焙成一个完全可微的模型。一个有趣的发现是,尽管在训练时从未明确提供过这种对应关系,但注意力间接地学习了音频和说话人脸之间的关联。在目前的工作中,我们进一步研究了这种联系并检查了这两个问题之间的相互作用。通过涉及超过 5 万小时的公共 YouTube 视频作为训练数据的实验,我们首先评估了注意力层在主动说话者选择任务上的准确性。其次,我们在更仔细的审查下表明,端到端模型的性能至少与一个相当大的两步系统一样好,该系统在各种噪声条件和平行人脸轨迹数量下利用硬决策边界。
-
-Reference
@inproceedings{DBLP:conf/icassp/BragaS21, author = {Otavio Braga and Olivier Siohan}, title = {A Closer Look at Audio-Visual Multi-Person Speech Recognition and Active Speaker Selection}, booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing, {ICASSP} 2021, Toronto, ON, Canada, June 6-11, 2021}, pages = {6863--6867}, publisher = , year = {2021}, url = {https://doi.org/10.1109/ICASSP39728.2021.9414160}, doi = {10.1109/ICASSP39728.2021.9414160}, timestamp = {Fri, 09 Jul 2021 13:04:25 +0200}, biburl = {https://dblp.org/rec/conf/icassp/BragaS21.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
96. Fusing Information Streams in End-to-End Audio-Visual Speech Recognition
-
在端到端视听语音识别中融合信息流
-
视听融合语音识别
-
摘要: 端到端声学语音识别已迅速获得广泛普及,并在许多研究中显示出可喜的结果。具体来说,联合变压器/CTC 模型在许多任务中提供了非常好的性能。然而,在嘈杂和失真的条件下,性能仍然显着下降。虽然视听语音识别可以在如此恶劣的条件下显着提高端到端模型的识别率,但如何最好地利用这些模型中关于声学和视觉信号质量和可靠性的任何可用信息尚不清楚。因此,我们考虑如何以最佳方式告知变压器/CTC 模型声学和视觉信息流的任何时变可靠性的问题。我们提出了一种新的融合策略,将可靠性信息纳入考虑注意机制的时间效应的决策融合网络中。与唇读句子 2 和 3(LRS2 和 LRS3)语料库上的最新基线模型相比,这种方法产生了显着的改进。平均而言,与纯音频设置相比,新系统的相对单词错误率降低了 43%,与视听端到端基线相比降低了 31%。
-
-Reference
@inproceedings{DBLP:conf/icassp/YuZK21, author = {Wentao Yu and Steffen Zeiler and Dorothea Kolossa}, title = {Fusing Information Streams in End-to-End Audio-Visual Speech Recognition}, booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing, {ICASSP} 2021, Toronto, ON, Canada, June 6-11, 2021}, pages = {3430--3434}, publisher = , year = {2021}, url = {https://doi.org/10.1109/ICASSP39728.2021.9414553}, doi = {10.1109/ICASSP39728.2021.9414553}, timestamp = {Mon, 03 Jan 2022 22:38:50 +0100}, biburl = {https://dblp.org/rec/conf/icassp/YuZK21.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
95. Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition
-
用于视听语音识别的基于Transformer的视频前端
-
摘要: 视听自动语音识别(AV-ASR)通过引入视频模态扩展了语音识别。特别是,说话者嘴部运动中包含的信息用于增强音频特征。视频模态传统上使用 3D 卷积神经网络(例如 VGG 的 3D 版本)进行处理。最近,图像变换网络 arXiv:2010.11929 展示了为图像分类任务提取丰富视觉特征的能力。在这项工作中,我们建议用视频转换器视频特征提取器替换 3D 卷积。我们在 YouTube 视频的大规模语料库上训练我们的基线和提出的模型。然后我们在 YouTube 的标记子集以及公共语料库 LRS3-TED 上评估性能。我们最好的纯视频模型在 YTDEV18 上实现了 34.9% WER 的性能,在 LRS3-TED 上实现了 19.3% 的性能,这比卷积基线分别提高了 10% 和 9%。在微调我们的模型 (1.6% WER) 后,我们在 LRS3-TED 上实现了最先进的视听识别性能。
-
-Reference
@article{DBLP:journals/corr/abs-2201-10439, author = {Dmitriy Serdyuk and Otavio Braga and Olivier Siohan}, title = {Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition}, journal = {CoRR}, volume = {abs/2201.10439}, year = {2022}, url = {https://arxiv.org/abs/2201.10439}, eprinttype = {arXiv}, eprint = {2201.10439}, timestamp = {Tue, 01 Feb 2022 14:59:01 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-2201-10439.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
94. Ultrasound-coupled semi-supervised nonnegative matrix factorisation for speech enhancement
-
用于语音增强的超声耦合半监督非负矩阵分解
-
摘要: 我们提出了对现有语音增强技术的扩展,其中结合容易获得的基于多普勒的超声数据(从说话者的嘴部运动引起的频移中获得)被证明可以改善语音增强结果。 使用半监督非负矩阵分解 (NMF) 增强了嘈杂的语音混合。 与语音一起记录的超声数据被转换为频谱域,并附加到要分离的混合物中的音频中。 语音分量是从训练集中学习的,而噪声分量是从混合信号中估计的。 我们表明,相对于非超声 NMF 情况和已建立的基于 Wiener 滤波器的语音增强方法,超声数据可以提高增强语音的源失真比。
-
-Reference :
@inproceedings{inproceedings, author = {Barker, Tom and Virtanen, Tuomas and Delhomme, Olivier}, year = {2014}, month = {05}, pages = {2129-2133}, title = {Ultrasound-coupled semi-supervised nonnegative matrix factorisation for speech enhancement}, isbn = {978-1-4799-2893-4}, journal = {ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings}, doi = {10.1109/ICASSP.2014.6853975} }
93. Speech enhancement using ultrasonic doppler sonar
-
超声多普勒声纳语音增强
- -Reference
@article{LEE201921, title = {Speech enhancement using ultrasonic doppler sonar}, journal = {Speech Communication}, volume = {110}, pages = {21-32}, year = {2019}, issn = {0167-6393}, doi = {https://doi.org/10.1016/j.specom.2019.03.008}, url = {https://www.sciencedirect.com/science/article/pii/S016763931830325X}, author = {Ki-Seung Lee}, } - 摘要: 使用传统的单通道语音增强方案再现的语音质量受到声学噪声水平的严重影响。非声学传感器能够揭示在嘈杂的声学信号中丢失的某些语音属性。本研究验证了使用由面部运动引起的超声多普勒频移来增强被高水平噪声污染的音频语音。一个 40 kHz 的超声波束入射到扬声器的脸上。接收到的信号首先被解调并转换为频谱特征参数。将超声多普勒信号 (UDS) 的频谱特征与嘈杂语音的频谱特征连接起来,然后将其用于估计干净语音的频谱幅度。在该估计中采用了非线性回归方法,其中音频-UDS 特征与相应的干净语音之间的关系由深度神经网络 (DNN) 表示。在 1 小时音频 UDS 语料库和四种不同类型的噪声数据上测试了所提出的增强方法的可行性。结果表明,无论是客观上还是主观上,当音频和UDS协同使用时,都获得了最好的性能。还进行了相关性分析以研究多向超声传感的有用性。结果表明,性能受采用的 UDS 通道数量的影响,尤其是在 SNR 水平较低的情况下。
92. A speech enhancement algorithm by iterating single- and multi-microphone processing and its application to robust ASR
-
一种迭代单麦克风和多麦克风处理的语音增强算法及其在鲁棒ASR中的应用
- -Reference
@INPROCEEDINGS{7952161, author={Zhang, Xueliang and Wang, Zhong-Qiu and Wang, DeLiang}, booktitle={2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={A speech enhancement algorithm by iterating single- and multi-microphone processing and its application to robust ASR}, year={2017}, volume={}, number={}, pages={276-280}, doi={10.1109/ICASSP.2017.7952161}} - 摘要: 我们提出了一种基于单麦克风和多麦克风处理技术的语音增强算法。该算法的核心是估计一个代表目标语音的时频掩码,并使用基于掩码的波束成形来增强损坏的语音。具体来说,在单麦克风处理中,麦克风阵列的接收信号被视为单独的信号,我们使用深度神经网络 (DNN) 估计每个麦克风的信号的掩码。使用这些掩码,在多麦克风处理中,我们计算了噪声的空间协方差矩阵和用于波束成形的转向矢量。此外,我们提出了一种基于掩蔽的后置滤波器,以进一步抑制波束成形输出中的噪声。然后,增强的语音被发送回 DNN 进行掩码重新估计。当这些步骤迭代几次时,我们得到最终的增强语音。所提出的算法被评估为自动语音识别(ASR)的前端,在 CHiME-3 的真实环境测试集上实现了 5.05% 的平均单词错误率(WER),优于当前最佳算法 13.34%。
91. Active Noise Cancellation With MEMS Resonant Microphone Array
-
采用 MEMS 谐振麦克风阵列的有源噪声消除
- -Reference
@ARTICLE{9158528, author={Liu, Hai and Liu, Song and Shkel, Anton A. and Kim, Eun Sok}, journal={Journal of Microelectromechanical Systems}, title={Active Noise Cancellation With MEMS Resonant Microphone Array}, year={2020}, volume={29}, number={5}, pages={839-845}, doi={10.1109/JMEMS.2020.3011938}} - 摘要: 本文介绍了基于 MEMS 谐振麦克风阵列 (RMA) 的有源噪声消除 (ANC),它在谐振频率附近提供非常高的灵敏度(因此本底噪声非常低),并且还提供声学域的滤波。 ANC 旨在主动消除 5-9 kHz 之间的任何声音(高于 300 - 3,400 Hz 的语音范围)。 ANC 在灵敏度高的谐振麦克风的谐振频率附近工作得最好。 ANC 已通过模拟逆变器、数字相位补偿器、数字自适应滤波器和深度学习实现,并显示在基于 RMA 和基于平带麦克风的 ANC 中使用数字自适应滤波器可以更好地执行。同时,当 5 - 9 kHz 以上的声音强度较低时,带有自适应滤波器的基于 RMA 的 ANC 在所测试的不同方法中效果最佳。已使用 ANC 测试了不同噪声(不同强度级别)下的自动语音识别。在所有测试案例中,ANC 提高了单词错误率。
90. Transformer-Based Online CTC/Attention End-To-End Speech Recognition Architecture
-
基于 Transformer 的在线 CTC/Attention 端到端语音识别架构
- -Reference :
@INPROCEEDINGS{9053165, author={Miao, Haoran and Cheng, Gaofeng and Gao, Changfeng and Zhang, Pengyuan and Yan, Yonghong}, booktitle={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Transformer-Based Online CTC/Attention End-To-End Speech Recognition Architecture}, year={2020}, volume={}, number={}, pages={6084-6088}, doi={10.1109/ICASSP40776.2020.9053165}} - 摘要: 最近,Transformer 在自动语音识别(ASR)领域取得了成功。然而,为在线语音识别部署基于 Transformer 的端到端 (E2E) 模型具有挑战性。在本文中,我们提出了基于 Transformer 的在线 CTC/注意力 E2E ASR 架构,它包含块自注意力编码器 (chunk-SAE) 和基于单调截断注意力 (MTA) 的自注意力解码器 (SAD)。首先,chunk-SAE 将语音分割成孤立的块。为了降低计算成本并提高性能,我们提出了状态重用chunk-SAE。其次,基于 MTA 的 SAD 单调地截断语音特征,并对截断的特征执行注意力。为了支持在线识别,我们将状态重用块 SAE 和基于 MTA 的 SAD 集成到在线 CTC/注意架构中。我们在 HKUST Mandarin ASR 基准测试中评估了所提出的在线模型,并在 320 毫秒的延迟下实现了 23.66% 的字符错误率 (CER)。与离线基线相比,我们的在线模型的绝对 CER 退化低至 0.19%,并且比我们之前在基于长短期记忆 (LSTM) 的在线 E2E 模型上的工作取得了显着改进。
89. Emformer: Efficient Memory Transformer Based Acoustic Model for Low Latency Streaming Speech Recognition
-
Emformer:基于高效记忆转换器的低延迟流语音识别声学模型
- -Reference :
@INPROCEEDINGS{9414560, author={Shi, Yangyang and Wang, Yongqiang and Wu, Chunyang and Yeh, Ching-Feng and Chan, Julian and Zhang, Frank and Le, Duc and Seltzer, Mike}, booktitle={ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Emformer: Efficient Memory Transformer Based Acoustic Model for Low Latency Streaming Speech Recognition}, year={2021}, volume={}, number={}, pages={6783-6787}, doi={10.1109/ICASSP39728.2021.9414560}} - 摘要: 本文提出了一种用于低延迟流语音识别的高效内存转换器 Emformer。在 Emformer 中,远程历史上下文被提炼到一个增强的内存库中,以降低 self-attention 的计算复杂性。缓存机制将 key 和 value 的计算保存在左侧上下文的 self-attention 中。 Emformer 在训练中应用并行块处理来支持低延迟模型。我们对基准 LibriSpeech 数据进行了实验。在 960 毫秒的平均延迟下,Emformer 在 test-clean 上获得 WER 2.50%,在 test-other 上获得 5.62%。与强大的基线增强记忆转换器 (AM-TRF) 相比,Emformer 获得 4.6 倍的训练加速和 18% 的解码相对实时因子 (RTF) 减少,相对 WER 减少 17% 在 test-clean 和 9% 在 test-其他。对于平均延迟为 80 毫秒的低延迟场景,Emformer 在 test-clean 上达到 WER 3.01%,在 test-other 上达到 7.09%。与具有相同延迟和模型大小的 LSTM 基线相比,Emformer 在 test-clean 和 test-other 上的 WER 相对降低分别为 9% 和 16%。
88. Memory-efficient Speech Recognition on Smart Devices
-
智能设备上的高效内存语音识别
- -Reference
@article{DBLP:journals/corr/abs-2102-11531, author = {Ganesh Venkatesh and Alagappan Valliappan and Jay Mahadeokar and Yuan Shangguan and Christian Fuegen and Michael L. Seltzer and Vikas Chandra}, title = {Memory-efficient Speech Recognition on Smart Devices}, journal = {CoRR}, volume = {abs/2102.11531}, year = {2021}, url = {https://arxiv.org/abs/2102.11531}, eprinttype = {arXiv}, eprint = {2102.11531}, timestamp = {Wed, 24 Feb 2021 15:42:45 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-2102-11531.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} } - 摘要: 循环换能器模型已成为当前和下一代智能设备上语音识别的有前途的解决方案。传感器模型在合理的内存占用范围内提供了具有竞争力的准确性,从而减轻了这些设备中的内存容量限制。然而,这些模型在每个输入时间步长上都从片外存储器访问参数,这会对设备电池寿命产生不利影响,并限制了它们在低功耗设备上的可用性。 我们通过优化模型架构和设计新颖的循环单元设计来解决传感器模型的内存访问问题。我们证明了 i) 模型的能量成本主要通过从片外存储器访问模型权重来控制,ii) 传感器模型架构对于确定对片外存储器的访问次数至关重要,并且仅模型大小不是一个好的代理,iii)我们的传感器模型优化和新颖的循环单元将片外内存访问减少了 4.5 倍,模型大小减少了 2 倍,同时对精度的影响最小。
87. Maskcyclegan-vc: learning non-parallel voice conversion with filling in frames
-
Maskcyclegan-VC:通过填充帧学习非并行语音转换
- -Reference :
@INPROCEEDINGS{9414851, author={Kaneko, Takuhiro and Kameoka, Hirokazu and Tanaka, Kou and Hojo, Nobukatsu}, booktitle={ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Maskcyclegan-VC: Learning Non-Parallel Voice Conversion with Filling in Frames}, year={2021}, volume={}, number={}, pages={5919-5923}, doi={10.1109/ICASSP39728.2021.9414851}} - 概要:在CycleGAN-VC2基础上,借鉴Bert及image inpainting的训练方法,对source speech添加mask, 并训练conversion网络对mask的区域进行fill.
- 文中尝试了几种不同的mask概率,包括:1)固定概率 2)在某一个概率范围内的随机选择. 实验发现,mask在概率[0,50]随机选择时效果最好。
-
文中尝试了几种不同的mask方式,包括:1)连续帧的mask 2)不连续帧的mask 3)对某一个频带范围进行mask 4)离散点的mask. 实验发现连续帧的mask形式,也即示意图中的$m$表现最好。
- 摘要: 非并行语音转换 (VC) 是一种无需并行语料库即可训练语音转换器的技术。基于循环一致的对抗性网络的 VC(CycleGAN-VC 和 CycleGAN-VC2)被广泛接受为基准方法。然而,由于它们掌握时频结构的能力不足,尽管最近在梅尔谱图声码器方面取得了进展,但它们的应用仅限于梅尔倒谱转换而不是梅尔谱图转换。为了克服这个问题,已经提出了 CycleGAN-VC3,它是 CycleGAN-VC2 的改进变体,它结合了一个称为时频自适应归一化 (TFAN) 的附加模块。然而,增加了学习参数的数量。作为替代方案,我们提出了 MaskCycleGAN-VC,它是 CycleGAN-VC2 的另一个扩展,使用称为填充帧 (FIF) 的新型辅助任务进行训练。使用 FIF,我们将时间掩码应用于输入梅尔谱图,并鼓励转换器根据周围帧填充缺失的帧。该任务允许转换器以自我监督的方式学习时频结构,并且无需额外的模块,例如 TFAN。对自然度和说话人相似度的主观评估表明,MaskCycleGAN-VC 在模型大小与 CycleGAN-VC2 相似的情况下优于 CycleGAN-VC2 和 CycleGAN-VC3。 1
86. Self-Supervised Learning for Audio-Visual Speaker Diarization
-
摘要: 说话人分类是寻找特定说话人的语音片段,已广泛应用于以人为中心的应用,例如视频会议或人机交互系统。 在本文中,我们提出了一种自我监督的音频-视频同步学习方法来解决说话人分类问题,而无需大量标记工作。 我们通过引入两个新的损失函数来改进以前的方法:动态三元组损失和多项式损失。 我们在真实世界的人机交互系统上对它们进行了测试,结果表明我们的最佳模型产生了 +8% F 1 分数的显着增益,并且降低了分类错误率。 最后,我们介绍了一种新的大规模音视频语料库,旨在填补中文音视频数据集的空白。
-
-Reference :
@INPROCEEDINGS{9054376, author={Ding, Yifan and Xu, Yong and Zhang, Shi-Xiong and Cong, Yahuan and Wang, Liqiang}, booktitle={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Self-Supervised Learning for Audio-Visual Speaker Diarization}, year={2020}, volume={}, number={}, pages={4367-4371}, doi={10.1109/ICASSP40776.2020.9054376}}
85. Audio-Visual Recognition of Overlapped Speech for the LRS2 Dataset
-
摘要: 迄今为止,重叠语音的自动识别仍然是一项极具挑战性的任务。受人类语音感知的双峰性质的启发,本文研究了使用视听技术进行重叠语音识别。解决了与构建视听语音识别 (AVSR) 系统相关的三个问题。首先,研究了基本架构设计,即 AVSR 系统的端到端和混合。其次,有目的地设计的模态融合门用于稳健地整合音频和视觉特征。第三,与包含显式语音分离和识别组件的传统流水线架构相比,还提出了一种使用无网格 MMI (LF-MMI) 判别标准一致优化的流线型和集成 AVSR 系统。所提出的 LF-MMI 时间延迟神经网络 (TDNN) 系统建立了 LRS2 数据集的最新技术。对从 LRS2 数据集模拟的重叠语音的实验表明,所提出的 AVSR 系统在字错误率 (WER) 绝对降低方面优于纯音频基线 LF-MMI DNN 系统高达 29.98%,并且产生的识别性能可与更复杂的流水线系统相媲美.与使用特征融合的基线 AVSR 系统相比,WER 减少的绝对性能提高了 4.89%。
- -Reference
@INPROCEEDINGS{9054127, author={Yu, Jianwei and Zhang, Shi-Xiong and Wu, Jian and Ghorbani, Shahram and Wu, Bo and Kang, Shiyin and Liu, Shansong and Liu, Xunying and Meng, Helen and Yu, Dong}, booktitle={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Audio-Visual Recognition of Overlapped Speech for the LRS2 Dataset}, year={2020}, volume={}, number={}, pages={6984-6988}, doi={10.1109/ICASSP40776.2020.9054127}} - ASR
84. Integrated Sensing and Communication with Millimeter Wave Full Duplex Hybrid Beamforming
-
毫米波全双工混合波束成形的集成传感和通信
- -Reference
@INPROCEEDINGS{9625266, author={Wang, Siyuan and Chen, Risheng and Zhao, Lou and Liu, Chunshan}, booktitle={2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall)}, title={Millimeter Wave Integrated Sensing and Communication with Hybrid Architecture in Vehicle to Vehicle Network}, year={2021}, volume={}, number={}, pages={01-06}, doi={10.1109/VTC2021-Fall52928.2021.9625266}} -
波束成形(Beamforming)
- 摘要: 近年来,集成传感和通信 (ISAC) 在提高频谱效率方面吸引了巨大的吸引力,使硬件和频谱共享能够同时进行传感和信令操作。由于其同时传输和接收能力,带内全双工 (FD) 被认为是 ISAC 应用的关键支持技术。在本文中,我们提出了一个基于 FD 的 ISAC 系统,该系统以毫米波 (mmWave) 频率运行,其中一个大规模多输入多输出 (MIMO) 基站 (BS) 节点采用混合模拟和数字 (A/D) 波束成形正在与下行链路 (DL) 多天线用户进行通信,并且在 BS 接收器处使用相同的波形来感知其覆盖环境中的雷达目标。我们开发了一种能够估计雷达目标的到达方向 (DoA)、范围和相对速度的传感算法。提出了一种用于设计 A/D 发射和接收波束形成器以及自干扰 (SI) 消除的联合优化框架,旨在最大限度地提高可实现的 DL 速率和雷达目标传感性能的准确性。我们的仿真结果考虑了第五代 (5G) 正交频分复用 (OFDM) 波形,验证了我们的方法在估计多个雷达目标的 DoA、范围和速度方面的高精度,同时最大限度地提高了 DL 通信速率。
83. Deep Reinforcement Learning Coordinated Receiver Beamforming for Millimeter-Wave Train-ground Communications
-
基于RX端的毫米波波束成形
-
摘要: 随着越来越多的人选择高铁(HSR)作为短途出行的交通工具,对高质量多媒体服务的需求也越来越大。毫米波(mm-wave)通信以其丰富的频谱资源,可以满足高铁对网络容量的高要求。此外,由于波长短,接收器 (RX) 可以在毫米波通信系统中配备天线阵列。然而,由于 HSR 高速运行,接收信号功率 (RSP) 在一个小区内变化迅速,与其他位置相比,它在小区边缘是最低的。因此,有必要对毫米波段 HSR 的 RX 波束赋形进行研究,以提高接收信号的质量。在本文中,我们专注于毫米波车地通信系统的 RX 波束形成。为了改进 RSP,我们提出了一种基于深度强化学习 (DRL) 的有效 RX 波束形成方案,并开发了一种深度 Qnetwork (DQN) 算法来训练和确定最佳 RX 波束方向,以最大化平均 RSP。通过广泛的模拟,我们证明了所提出的方案在铁路上大多数位置的平均 RSP 方面比四个基线方案具有更好的性能。
-
-Reference :
@ARTICLE{9720922, author={Zhou, Xutao and Zhang, Xiangfei and Chen, Chen and Niu, Yong and Han, Zhu and Wang, He and Sun, Chengjun and Ai, Bo and Wang, Ning}, journal={IEEE Transactions on Vehicular Technology}, title={Deep Reinforcement Learning Coordinated Receiver Beamforming for Millimeter-Wave Train-ground Communications}, year={2022}, volume={}, number={}, pages={1-1}, doi={10.1109/TVT.2022.3153928}}
82.A Case for Digital Beamforming at mmWave
-
毫米波(mmWave)波束成形(beamforming)
-
摘要: 由于毫米波 (mmWave) 无线系统对定向链路的严重依赖,具有高维阵列的波束成形 (BF) 对于这些频率的蜂窝系统至关重要。因此,以节能的方式执行阵列处理是一项基本挑战。模拟和混合 BF 需要很少的模数和数模转换器(ADC 和 DAC),但一次只能在少量方向上通信,限制了方向搜索、空间复用和控制信令。数字BF支持灵活的空间处理,但必须以低量化分辨率运行以保持在合理的功率水平内。量化器分辨率的这种降低会使接收信号和发射信号失真。为了评估接收端粗量化的效果,本文提出了一种基于简单加性量化噪声模型(AQNM)的系统级分析框架。通过大量模拟验证的分析表明,在中等分辨率(每个 ADC 3-4 位)下,量化下行链路蜂窝容量的损失可以忽略不计。从本质上讲,低分辨率 ADC 限制了蜂窝系统通常无法运行的高 SNR。对于发射机,表明具有 4 位或更多位分辨率的 DAC 可以支持高阶调制,并且不会违反第三代合作伙伴计划 (3GPP) 新无线电 (NR) 蜂窝操作标准设置的相邻载波泄漏限制.事实上,我们的研究结果表明,对于毫米波发射器和接收器,低分辨率数字 BF 架构可以成为模拟或混合 BF 的节能替代方案。
-
-Reference :
@ARTICLE{8883297, author={Dutta, Sourjya and Barati, C. Nicolas and Ramirez, David and Dhananjay, Aditya and Buckwalter, James F. and Rangan, Sundeep}, journal={IEEE Transactions on Wireless Communications}, title={A Case for Digital Beamforming at mmWave}, year={2020}, volume={19}, number={2}, pages={756-770}, doi={10.1109/TWC.2019.2948329}}
81. Joint Training of Complex Ratio Mask Based Beamformer and Acoustic Model for Noise Robust Asr
-
摘要: 在本文中,我们提出了一个多通道波束形成器和噪声鲁棒自动语音识别(ASR)声学模型之间的联合训练框架。复比率掩膜 (CRM) 被证明比理想比率掩膜 (IRM) 更有效,被提议用于估计波束形成器的协方差矩阵。最小方差无失真响应 (MVDR) 波束形成器和广义特征值 (GEV) 波束形成器均在基于 CRM 的联合训练架构下进行了研究。我们还提出了一个强大的多通道掩码池策略。使用基于长短期记忆 (LSTM) 的语言模型对假设进行重新评分,从而进一步提高整体性能。我们在 CHiME-4 挑战数据集上评估提出的方法。与基于 IRM 的系统相比,基于 CRM 的系统的单词错误率 (WER) 相对降低了 10%。在没有序列判别训练的情况下,我们最好的单个系统已经在测试集上达到了平均 WER 2.72%,这与最先进的技术相当。
-
-Reference :
@INPROCEEDINGS{8682576, author={Xu, Yong and Weng, Chao and Hui, Like and Liu, Jianming and Yu, Meng and Su, Dan and Yu, Dong}, booktitle={ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Joint Training of Complex Ratio Mask Based Beamformer and Acoustic Model for Noise Robust Asr}, year={2019}, volume={}, number={}, pages={6745-6749}, doi={10.1109/ICASSP.2019.8682576}}
80. Enhancing End-to-End Multi-Channel Speech Separation Via Spatial Feature Learning
-
摘要: 手工制作的空间特征(例如,通道间相位差,IPD)在最近基于深度学习的多通道语音分离(MCSS)方法中发挥着重要作用。然而,这些人工设计的空间特征很难融入到端到端优化的 MCSS 框架中。在这项工作中,我们提出了一种集成架构,用于直接从端到端语音分离框架内的多通道语音波形中学习空间特征。在这个架构中,跨越信号通道的时域滤波器被训练来执行自适应空间滤波。这些滤波器由 2d 卷积 (conv2d) 层实现,并且它们的参数使用语音分离目标函数以纯数据驱动的方式进行优化。此外,受 IPD 公式的启发,我们设计了一个 conv2d 内核来计算通道间卷积差异 (ICD),它有望提供有助于区分方向源的空间线索。模拟多通道混响 WSJ0 2-mix 数据集的评估结果表明,我们提出的基于 ICD 的 MCSS 模型比基于 IPD 的 MCSS 模型提高了 10.4% 的整体信号失真比。
-
-Reference :
@INPROCEEDINGS{9053092, author={Gu, Rongzhi and Zhang, Shi-Xiong and Chen, Lianwu and Xu, Yong and Yu, Meng and Su, Dan and Zou, Yuexian and Yu, Dong}, booktitle={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Enhancing End-to-End Multi-Channel Speech Separation Via Spatial Feature Learning}, year={2020}, volume={}, number={}, pages={7319-7323}, doi={10.1109/ICASSP40776.2020.9053092}}
79. Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone
-
摘要: 仅使用单个远距离麦克风 (SDM) 转录包含重叠语音的会议一直是自动语音识别 (ASR) 最具挑战性的问题之一。虽然已经提出了各种方法,但之前所有关于单声道重叠语音识别问题的研究都是基于模拟数据或小规模真实数据。在本文中,我们广泛研究了一种两步方法,首先使用大规模仿真数据预训练基于序列化输出训练 (SOT) 的多说话者 ASR,然后使用少量真实的会议数据。实验是利用 75,000 (K) 小时的内部单人录音来模拟总共 900,000 小时的多人音频片段,以进行有监督的预训练。通过对 AMI-SDM 训练数据的 70 小时进行微调,我们的 SOT ASR 模型在 AMI-SDM 评估集上实现了 21.2% 的单词错误率 (WER),同时自动计算每个测试段中的发言者。这一结果不仅明显优于先前具有预言机话语边界信息的最先进的 36.4% 的 WER,而且也优于应用于波束成形音频的类似微调的单说话者 ASR 模型的结果。
-
-Reference :
@misc{https://doi.org/10.48550/arxiv.2103.16776, doi = {10.48550/ARXIV.2103.16776}, url = {https://arxiv.org/abs/2103.16776}, author = {Kanda, Naoyuki and Ye, Guoli and Wu, Yu and Gaur, Yashesh and Wang, Xiaofei and Meng, Zhong and Chen, Zhuo and Yoshioka, Takuya}, title = {Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone}, publisher = {arXiv}, year = {2021}, copyright = {arXiv.org perpetual, non-exclusive license} }
78. The enhancement of millimeter wave conduct speech based on perceptual weighting
-
基于感知加权的毫米波传导语音增强
-
摘要: 本文介绍了一种基于毫米波(MMW)雷达的非空气传导语音检测新方法。由于其特殊的属性,这种方法可以提供一些令人兴奋的广泛应用的可能性。然而,由于存在组合的和有色的加性噪声,因此产生的语音难以理解且可听性差。因此,本文通过考虑人类听觉系统的频域掩蔽特性来研究毫米波雷达语音增强问题,并降低残余噪声的感知效应。考虑到MMW语音的特殊特性,开发了感知加权技术并将其纳入传统的谱减法算法中,对残余噪声进行整形,使其听不见。声学和听力评估的结果表明,可以有效降低背景噪声,而毫米波雷达语音的失真仍然可以接受,增强后的语音对人类听众来说听起来也更悦耳,这表明所提出的算法实现了更好的降噪性能优于其他减法类型的算法。
@article{article, author = {Li, Sheng and Wang, Jian-Qi and Niu, Ming and Liu, Tian and Jing, Xi-Jing}, year = {2008}, month = {01}, pages = {199-214}, title = {The enhancement of millimeter wave conduct speech based on perceptual weighting}, volume = {9}, journal = {Progress in Electromagnetics Research B}, doi = {10.2528/PIERB08063001}}
77. A New Kind of Non-Acoustic Speech Acquisition Method Based on Millimeter Waveradar
-
摘要: 空气不是唯一可以传播并且可用于检测语音的介质。在我们之前的论文中,引入了另一种有价值的中毫米波 (MMW) 来开发一种新的语音采集技术 [Li et al., Progress In Electromagnetics Research B, 9, 199-214, 2008]。由于毫米波雷达的特殊特性,这种语音采集方法可以为广泛的应用提供一些令人兴奋的可能性。在拟议的研究中,我们设计了一种新型语音采集雷达系统。新系统中使用了超外差接收器,以减轻严重的直流偏移问题和相关的基带 1/f 噪声。此外,为了减少MMW检测语音中的谐波噪声、电路噪声和环境噪声,本研究还提出了一种自适应小波包熵算法,该算法结合了基于小波包熵的语音/清音。小波包时间尺度自适应语音增强过程中的雷达语音自适应检测方法和人耳感知特性。所提出的方法的性能通过信噪比客观地评估,主观地通过平均意见分数来评估。结果证实,所提出的方法对毫米波雷达语音的其他传统语音增强方法具有改进的效果。
76. The application of perceptual weighting on millimeter wave conducted speech enhancement
-
摘要: 本文介绍了一种利用毫米波(MMW)雷达的非空中行为语音检测新方法。由于其特殊的属性,这种方法可以提供一些令人兴奋的广泛应用的可能性。然而,由于存在组合的和有色的加性噪声,因此产生的语音难以理解且可听性差。因此,本文研究了毫米波雷达语音增强问题,考虑到人类听觉系统的频域掩蔽特性,降低了残余噪声的感知效应。考虑到MMW语音的特殊特性,开发了感知加权技术并将其纳入传统的谱减法算法中,对残余噪声进行整形,使其听不见。声学和听力评估的结果表明,可以有效降低背景噪声,而毫米波雷达语音的失真仍然可以接受,增强后的语音对人类听众来说听起来也更悦耳,这表明所提出的算法实现了更好的降噪性能优于其他减法类型的算法。
-
-Reference :
@inproceedings{DBLP:conf/icnc/LiWJL10, author = {Sheng Li and Jianqi Wang and XiJing Jing}, title = {The application of perceptual weighting on millimeter wave conducted speech enhancement}, booktitle = {Sixth International Conference on Natural Computation, {ICNC} 2010, Yantai, Shandong, China, 10-12 August 2010}, pages = {3230--3233}, publisher = , year = {2010}, url = {https://doi.org/10.1109/ICNC.2010.5584573}, doi = {10.1109/ICNC.2010.5584573}, timestamp = {Wed, 16 Oct 2019 14:14:55 +0200}, biburl = {https://dblp.org/rec/conf/icnc/LiWJL10.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
75. A Novel Method for Speech Acquisition and Enhancement by 94 GHz Millimeter-Wave Sensor
-
一种利用 94 GHz 毫米波传感器进行语音采集和增强的新方法
-
摘要: 为了提高非接触式方法的语音采集能力,采用 94 GHz 毫米波 (MMW) 雷达传感器检测语音信号。这种新颖的非接触式语音采集方法被证明具有高方向灵敏度,并且不受强声学干扰的影响。然而,毫米波雷达语音经常受到组合噪声源的影响,主要包括谐波、电路和信道噪声。本文提出了一种结合经验模态分解(EMD)和互信息熵(MIE)的算法来增强雷达语音的可感知性和可理解性。首先,雷达语音信号通过 EMD 自适应地分解为称为固有模式函数 (IMF) 的振荡分量。其次,使用 MIE 确定重构分量的数量,然后采用自适应阈值去除雷达语音中的噪声。实验结果表明,94 GHz毫米波雷达传感器在检测距离为20 m时可以有效地获取人类语音。此外,雷达语音的噪声被大大抑制,语音声音在被提出的算法增强后变得更悦耳,这表明这种新颖的语音采集和增强方法将为与语音检测相关的各种应用提供有希望的替代方案.
-
-Reference :
@Article{s16010050, AUTHOR = {Chen, Fuming and Li, Sheng and Li, Chuantao and Liu, Miao and Li, Zhao and Xue, Huijun and Jing, Xijing and Wang, Jianqi}, TITLE = {A Novel Method for Speech Acquisition and Enhancement by 94 GHz Millimeter-Wave Sensor}, JOURNAL = {Sensors}, VOLUME = {16}, YEAR = {2016}, NUMBER = {1}, ARTICLE-NUMBER = {50}, URL = {https://www.mdpi.com/1424-8220/16/1/50}, PubMedID = {26729126}, ISSN = {1424-8220}, DOI = {10.3390/s16010050} }
74. Hearing Your Voice is Not Enough: An Articulatory Gesture Based Liveness Detection for Voice Authentication
- CCS‘2017
- 摘要: 语音生物识别技术正引起越来越多的关注,因为它是用于移动身份验证的传统密码的有前途的替代方案。最近,越来越多的工作表明,语音生物识别技术容易受到重放攻击的欺骗,对手试图通过使用从真实用户那里收集的预先录制的语音样本来欺骗语音认证系统。在这项工作中,我们提出了 VoiceGesture,一种用于智能手机重放攻击检测的活体检测系统。它通过利用用户在说出密码时独特的发音手势和移动音频硬件的进步来检测现场用户。具体来说,我们的系统将智能手机重新用作多普勒雷达,它从内置扬声器传输高频声学声音,并在用户说出密码短语时听取麦克风的反射。由于用户的发音姿势导致的信号反射导致多普勒频移,然后对其进行分析以进行实时用户检测。 VoiceGesture 非常实用,因为它既不需要繁琐的操作,也不需要额外的硬件,只需要智能手机上常见的扬声器和麦克风。我们对 21 名参与者和不同类型手机的实验评估表明,它在大约 1% 的等误码率 (EER) 下实现了超过 99% 的检测准确率。结果还表明,它对不同的电话放置很稳健,并且能够使用不同的采样频率。
73. Learning Audio-visual Speech Representations by Masked Multimodal Cluster Prediction
- 通过蒙面多模态聚类预测学习视听语音表示
- ICLR’2022
- Code:https://github.com/facebookresearch/av_hubert
-
摘要: 语音的视频记录包含相关的音频和视觉信息,为从说话者的嘴唇运动和产生的声音中学习语音表征提供了强大的信号。我们介绍了视听隐藏单元 BERT (AV-HuBERT),这是一种用于视听语音的自我监督表示学习框架,它可以屏蔽多流视频输入并预测自动发现和迭代细化的多模态隐藏单元。 AV-HuBERT 学习强大的视听语音表示,有利于唇读和自动语音识别。在最大的公共唇读基准 LRS3(433 小时)上,AV-HuBERT 仅用 30 小时的标记数据就达到了 32.5% 的 WER,超过了之前经过一千倍以上训练的最先进方法(33.6%)转录视频数据(31K 小时)(Makino 等人,2019 年)。当使用来自 LRS3 的所有 433 小时标记数据并结合自我训练时,唇读 WER 进一步降低到 26.9%。在相同的纯音频语音识别基准上使用我们的视听表示,与最先进的性能相比,WER 相对降低了 40%(1.3% 对 2.3%)。
-
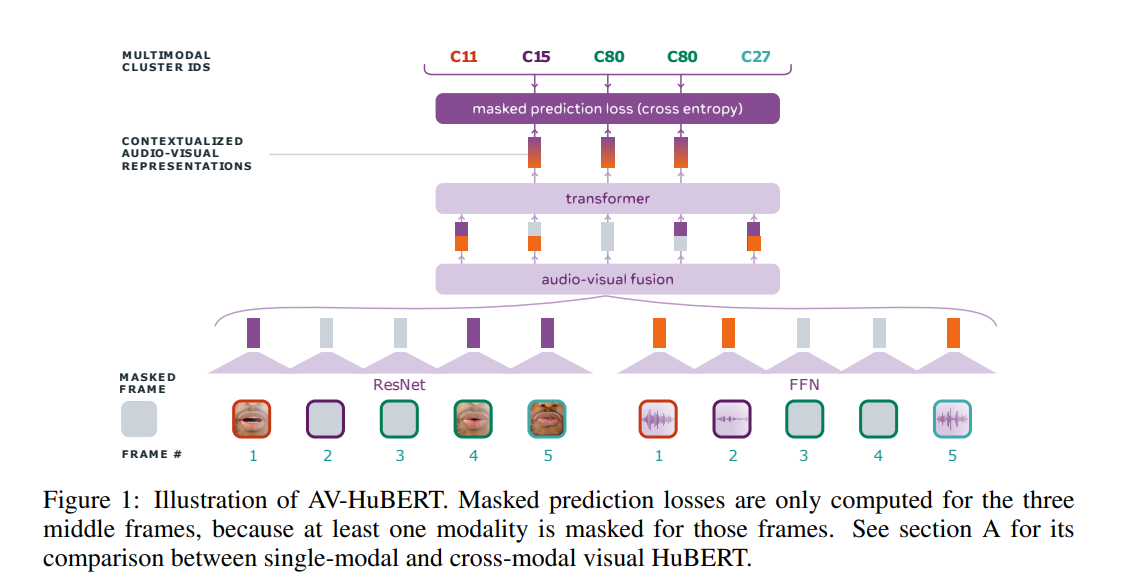
72. Deep Iterative Collaboration for Face Super-Resolution
-
CVPR 2020
-
摘要: 最近基于深度学习和面部先验的工作已经成功地超分辨率严重退化的面部图像。然而,现有方法中没有充分利用先验知识,因为诸如地标和分量图之类的面部先验总是通过低分辨率或粗略的超分辨率图像估计,这可能不准确,从而影响恢复性能。在本文中,我们提出了一种深度人脸超分辨率(FSR)方法,在两个循环网络之间进行迭代协作,分别关注人脸图像恢复和地标估计。在每个循环步骤中,恢复分支利用地标的先验知识来产生更高质量的图像,从而促进更准确的地标估计。因此,两个进程之间的迭代信息交互逐步提升了彼此的性能。此外,还设计了一个新的注意力融合模块来加强地标地图的引导,其中面部组件单独生成并集中聚合以更好地恢复。定量和定性实验结果表明,所提出的方法在恢复高质量人脸图像方面明显优于最先进的 FSR 方法。
71.Perceptual Extreme Super Resolution Network with Receptive Field Block
- 摘要: Perceptual Extreme Super-Resolution 对于单张图像来说是极其困难的,因为不同图像的纹理细节差异很大。为了解决这个难题,我们开发了一个基于增强型 SRGAN 的带有感受野块的超分辨率网络。我们称我们的网络为 RFB-ESRGAN。主要贡献如下。首先,为了提取多尺度信息并增强特征可辨别性,我们将感受野块(RFB)应用于超分辨率。 RFB 在目标检测和分类方面取得了具有竞争力的成果。其次,在多尺度感受野块中没有使用大卷积核,而是在 RFB 中使用了几个小核,这使得我们能够提取详细的特征并降低计算复杂度。第三,我们在上采样阶段交替使用不同的上采样方法,以降低高计算复杂度,仍然保持令人满意的性能。第四,我们使用 10 个不同迭代的模型的集成来提高模型的鲁棒性并减少每个单独模型引入的噪声。我们的实验结果显示了 RFB-ESRGAN 的优越性能。根据NTIRE 2020 Perceptual Extreme Super-Resolution Challenge的初步结果,我们的解决方案在所有参赛者中排名第一。
70. Correction Filter for Single Image Super-Resolution: Robustifying Off-the-Shelf Deep Super-Resolvers
- CVPR 2020
- Paper:https://arxiv.org/abs/1912.00157
- Code:https://github.com/shadyabh/Correction-Filter
-
Analysis:Correction Filter for Single Image Super-Resolution阅读笔记(CVPR2020)
- 摘要: 单幅图像超分辨率任务是过去十年中研究最多的逆问题之一。近年来,当采集过程使用固定的已知下采样内核(通常是双三次内核)时,深度神经网络 (DNN) 表现出优于替代方法的性能。然而,最近的几项工作表明,在测试数据与训练数据不匹配的实际场景中(例如,当下采样内核不是双三次内核或在训练时不可用时),领先的 DNN 方法会遭受巨大的性能下降。受广义采样文献的启发,在这项工作中,我们提出了一种方法来提高 DNN 的性能,这些 DNN 已经用固定内核对其他内核获得的观察结果进行了训练。对于已知的内核,我们设计了一个封闭形式的校正滤波器,它修改低分辨率图像以匹配另一个内核(例如双三次)获得的图像,从而改善现有预训练 DNN 的结果。对于一个未知的内核,我们扩展了这个想法,并提出了一种对所需校正滤波器进行盲估计的算法。我们表明,我们的方法优于其他为通用下采样内核设计的超分辨率方法。
69. Unpaired Image Super-Resolution Using Pseudo-Supervision
- CVPR 2020
- 关键词:Image Super-Resolution, GAN
- 摘要: 在大多数关于基于学习的图像超分辨率 (SR) 的研究中,配对训练数据集是通过使用预定操作(例如双三次)缩小高分辨率 (HR) 图像来创建的。然而,这些方法无法超分辨率真实世界的低分辨率(LR)图像,其退化过程更加复杂和未知。在本文中,我们提出了一种使用生成对抗网络的非配对 SR 方法,该方法不需要配对/对齐的训练数据集。我们的网络由一个不成对的核/噪声校正网络和一个伪成对的 SR 网络组成。校正网络去噪,调整输入LR图像的核;然后,校正后的干净 LR 图像由 SR 网络放大。在训练阶段,校正网络还从输入的 HR 图像中生成伪干净的 LR 图像,然后由 SR 网络以配对的方式学习从伪干净的 LR 图像到输入的 HR 图像的映射。因为我们的 SR 网络独立于校正网络,所以经过充分研究的现有网络架构和逐像素损失函数可以与所提出的框架集成。在不同数据集上的实验表明,所提出的方法优于现有的未配对 SR 问题的解决方案。
68. EventSR: From Asynchronous Events to Image Reconstruction, Restoration, and Super-Resolution via End-to-End Adversarial Learning
- CVPR 2020
- 关键词:Image Super-Resolution,
- 摘要: 事件摄像机可感知强度变化,并且与传统摄像机相比具有许多优势。为了利用事件相机,已经提出了一些方法来从事件流中重建强度图像。但是,输出仍然处于低分辨率 (LR)、嘈杂和不切实际的状态。低质量输出推动了事件摄像机的更广泛应用,其中需要高空间分辨率 (HR) 以及高时间分辨率、动态范围和无运动模糊。当没有地面实况 (GT) HR 图像和下采样内核可用时,我们考虑从纯事件重建和超分辨强度图像的问题。为了应对这些挑战,我们提出了一种新颖的端到端管道,它从事件流中重建 LR 图像,增强图像质量并对增强后的图像进行上采样,称为 EventSR。由于没有真实的 GT 图像,我们的方法主要是无监督的,部署对抗学习。为了训练 EventSR,我们创建了一个包含真实场景和模拟场景的开放数据集。这两个数据集的使用提高了网络性能,每个阶段的网络架构和各种损失函数有助于提高图像质量。整个管道分三个阶段进行训练。虽然每个阶段主要针对三个任务之一,但早期阶段的网络通过各自的损失函数以端到端的方式进行微调。实验结果表明,EventSR 从模拟和真实世界数据的事件中生成高质量的 SR 图像。
67. Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution
- CVPR 2020
- 关键词:Image Super-Resolution,
- 摘要: 深度神经网络通过学习从低分辨率 (LR) 图像到高分辨率 (HR) 图像的非线性映射函数,在图像超分辨率 (SR) 方面表现出良好的性能。然而,现有的 SR 方法有两个潜在的限制。首先,学习从 LR 到 HR 图像的映射函数通常是一个不适定问题,因为存在无限的 HR 图像可以下采样到相同的 LR 图像。结果,可能的功能空间可能非常大,这使得很难找到一个好的解决方案。其次,配对的 LR-HR 数据在实际应用中可能不可用,并且底层的退化方法通常是未知的。对于这种更一般的情况,现有的 SR 模型通常会导致适应问题并产生较差的性能。为了解决上述问题,我们提出了一种对偶回归方案,通过对 LR 数据引入额外的约束来减少可能函数的空间。具体来说,除了从 LR 到 HR 图像的映射之外,我们还学习了一个额外的对偶回归映射估计下采样内核并重建 LR 图像,这形成了一个闭环以提供额外的监督。更关键的是,由于对偶回归过程不依赖于 HR 图像,我们可以直接从 LR 图像中学习。从这个意义上说,我们可以轻松地将 SR 模型适应现实世界的数据,例如来自 YouTube 的原始视频帧。对配对训练数据和非配对现实世界数据的广泛实验证明了我们优于现有方法的优势。
66. PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
- CVPR 2020
- 关键词:Image Super-Resolution,
- Code
-
Analysis:杜克大学提出 AI 算法,拯救渣画质马赛克秒变高清
- 摘要: 单图像超分辨率的主要目的是从相应的低分辨率 (LR) 输入构建高分辨率 (HR) 图像。在通常受到监督的先前方法中,训练目标通常测量超分辨率 (SR) 和 HR 图像之间的像素平均距离。优化此类指标通常会导致模糊,尤其是在高方差(详细)区域中。我们提出了一种基于创建正确缩小比例的真实 SR 图像的超分辨率问题的替代公式。我们提出了一种算法来解决这个问题,PULSE(通过潜在空间探索的照片上采样),它以文献中以前未见的分辨率生成高分辨率、逼真的图像。它以完全自我监督的方式完成此任务,并且不限于在训练期间使用的特定退化算子,这与以前的方法(需要对 LR-HR 图像对的数据库进行监督训练)不同。 PULSE 不是从 LR 图像开始慢慢添加细节,而是遍历高分辨率自然图像流形,搜索缩小到原始 LR 图像的图像。这是通过“缩小损失”形式化的,它引导探索生成模型的潜在空间。通过利用高维高斯的特性,我们限制搜索空间以保证真实的输出。因此,PULSE 可以生成真实且正确缩小比例的超分辨率图像。我们在人脸超分辨率(即人脸幻觉)领域展示了我们方法的概念证明。我们还讨论了当前使用带有相关指标的随附模型卡实现的方法的局限性和偏差。我们的方法在比以前可能的更高的分辨率和比例因子下的感知质量优于最先进的方法。
65. M-Cube: A Millimeter-Wave Massive MIMO Software Radio
- 阅读时间:2022.2.16
- MobiCom2020
- 设计硬件,毫米波软件无线电
- M3 Project
-
摘要: 毫米波 (mmWave) 技术代表了新兴无线网络基础设施以及安全、健康和汽车领域的 RF 传感系统的基石。通过具有数百个天线元件的相控阵 MIMO 阵列,毫米波可以将无线比特率提高到 100+ Gbps,并有可能实现近视传感分辨率。然而,缺乏实验平台一直阻碍着该领域的研究。本文填补了 M3 (M-Cube) 的空白,这是第一个毫米波大规模 MIMO 软件无线电。 M3 具有完全可重构的相控阵阵列,具有多达 8 个射频链和 288 个天线单元。尽管天线阵列大了几个数量级,但它的成本却低了几个数量级,即使与最先进的单射频链毫米波软件无线电相比也是如此。 M3 背后的关键设计原理是劫持低成本的商用 802.11ad 无线电,分离内部的控制路径和数据路径,重新生成相控阵控制信号,并使用可编程基带重新创建数据信号。大量实验证明了 M3 设计的有效性,及其在毫米波大规模 MIMO 通信和传感研究中的有用性。
- 介绍:为了充分探索毫米波技术的挑战和机遇,关键是要有一个具有以下功能的可编程实验平台:
- 配备低成本和大规模相控阵,可实现实时波束切换,以适应高移动性的车辆网络/传感场景;
- 支持用于5G NR和802.11ay无线电的mmWave MIMO架构
- 允许重新配置波束模式,通信/传感算法和网络堆栈
64. Image Inpainting for Irregular Holes Using Partial Convolutions
- ECCV 2018
-
文章指出,以往图像补全技术都是用残缺位置周边的有效像素统计信息填充目标区域,这种做法虽然结果平滑,但存在效果不逼真、有伪像,且后期处理代价昂贵的缺点。因此他们用大量不规则掩膜图像训练了一个深度神经网络,它能为图像生成合理掩膜,再结合仅以有效像素为条件的部分卷积(Partial Convolutions),最终模型的图像补全效果远超前人的成果。
-
摘要: 现有的基于深度学习的图像修复方法在损坏的图像上使用标准卷积网络,使用以有效像素和掩蔽孔中的替代值(通常是平均值)为条件的卷积滤波器响应。 这通常会导致伪影,例如颜色差异和模糊。 后处理通常用于减少此类伪影,但价格昂贵且可能会失败。 我们建议使用部分卷积,其中卷积被屏蔽并重新归一化以仅以有效像素为条件。 我们还包括一种机制,可以自动为下一层生成更新的掩码,作为前向传递的一部分。 我们的模型优于其他不规则蒙版的方法。 我们展示了与其他方法的定性和定量比较,以验证我们的方法。

63. Self2Self With Dropout: Learning Self-Supervised Denoising From Single Image
- 阅读时间:2022.2.23
- CVPR 2020
-
关键词:PuNet, 图像去噪,自监督学习
- 摘要: 在过去的几年里,有监督的深度学习已经成为一种强大的图像去噪工具,它在噪声/干净图像对的外部数据集上训练去噪网络。然而,对高质量训练数据集的要求限制了去噪网络的广泛适用性。最近,有一些作品只允许在一组外部噪声图像上训练去噪网络。更进一步,本文提出了一种仅使用输入噪声图像本身进行训练的自监督学习方法。在所提出的方法中,网络在输入图像的伯努利采样实例对上进行了 dropout 训练,并通过对从训练模型的多个实例生成的预测进行平均来估计结果。实验表明,所提出的方法不仅显着优于现有的单图像学习或非学习方法,而且与在外部数据集上训练的去噪网络具有竞争力。
62. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- ICLR 2016
- 关键词:DCGANs
- 摘要:
61. Detection of the Vibration Signal from Human Vocal Folds Using a 94-GHz Millimeter-Wave Radar
- 阅读时间: 2022.2.21
-
关键词:94GHz Millimter-Wave 测量声带振动
-
摘要:
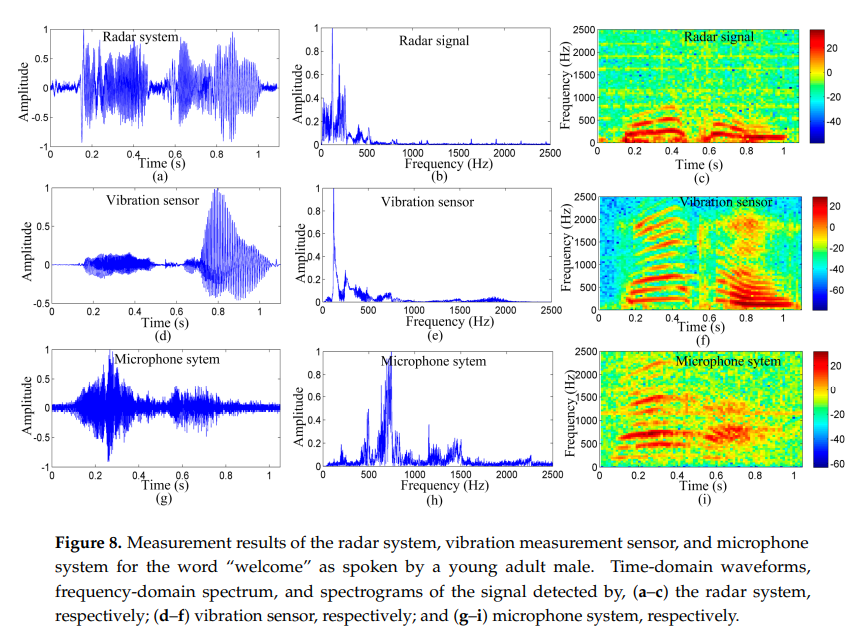
人类声带振动信号的检测为研究人类发声和诊断声音障碍提供了重要的信息。多普勒雷达技术使非接触测量人的声带振动成为可能。然而,现有的系统必须放置在靠近人的喉咙和详细的信息可能会丢失,因为低工作频率。本文提出了一种利用94-GHz毫米波雷达传感器检测人类声带振动信号的远程检测方法。提出了一种结合经验模态分解(EMD)和自相关函数(ACF)的信号检测算法。首先,采用EMD方法抑制雷达探测信号中的噪声;然后,利用能量和熵的比值检测雷达检测到的信号中的语音活动,然后利用短时ACF从处理后的信号中提取出人类声带的振动信号。为了验证该方法的有效性和评估雷达系统的性能,另外还采用了振动测量传感器和传声器系统进行比较。从声谱图、声带振动频率和相干性分析得到的实验结果表明,该方法可以在较长的探测距离内有效地检测人体声带的振动。 - 整体结构:
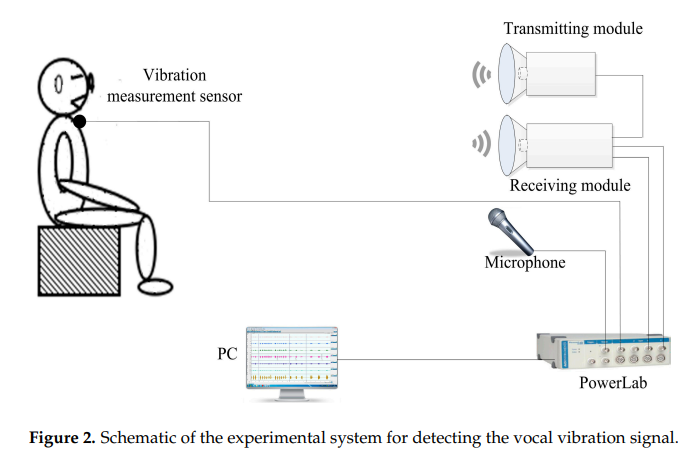
- 实验细节:对比毫米波雷达系统和麦克风采集的语音“Welcome”
60. Efficient Conditional GAN Transfer with Knowledge Propagation across Classes
- 阅读时间:2022.2.22
- 关键词:GAN,
-
@INPROCEEDINGS{8237506, author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A.}, booktitle={2017 IEEE International Conference on Computer Vision (ICCV)}, title={Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks}, year={2017}, volume={}, number={}, pages={2242-2251}, doi={10.1109/ICCV.2017.244}} - 摘要: 图像到图像转换是一类视觉和图形问题,其目标是使用一组对齐的图像对来学习输入图像和输出图像之间的映射。但是,对于许多任务,配对训练数据将不可用。我们提出了一种在没有配对示例的情况下学习将图像从源域 X 转换到目标域 Y 的方法。我们的目标是学习一个映射 G : X → Y,使得来自 G(X) 的图像分布与使用对抗性损失的分布 Y 无法区分。因为这个映射是高度欠约束的,我们将它与逆映射 F : Y → X 结合起来,并引入循环一致性损失来推动 F(G(X)) ≈ X(反之亦然)。在不存在配对训练数据的几个任务上给出了定性结果,包括集合风格迁移、对象变形、季节迁移、照片增强等。与几种先前方法的定量比较证明了我们方法的优越性。
59. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
- 阅读时间:2022.2.21
- 出处: ICCV 2017
- 关键词: Cycle-GAN, Unpaired Image-to-Image Translation
- paper: https://ieeexplore.ieee.org/document/8237506
- 摘要: 图像到图像转换是一类视觉和图形问题,其目标是使用一组对齐的图像对来学习输入图像和输出图像之间的映射。但是,对于许多任务,配对训练数据将不可用。我们提出了一种在没有配对示例的情况下学习将图像从源域 X 转换到目标域 Y 的方法。我们的目标是学习一个映射 G : X → Y,使得来自 G(X) 的图像分布与使用对抗性损失的分布 Y 无法区分。因为这个映射是高度欠约束的,我们将它与逆映射 F : Y → X 结合起来,并引入循环一致性损失来推动 F(G(X)) ≈ X(反之亦然)。在不存在配对训练数据的几个任务上给出了定性结果,包括集合风格迁移、对象变形、季节迁移、照片增强等。与几种先前方法的定量比较证明了我们方法的优越性。
58. PHASEN: A Phase-and-Harmonics-Aware Speech Enhancement Network
- 阅读时间:2022.2.16
-
AAAI 2020
- 摘要: 时频 (T-F) 域掩蔽是单通道语音增强的主流方法。近来,除了幅度预测之外,还关注相位预测。在本文中,我们为此任务提出了一个相位和谐波感知深度神经网络 (DNN),名为 PHASEN。与之前直接使用复杂的理想比率掩码来监督 DNN 学习的方法不同,我们设计了一个双流网络,其中幅度流和相位流专用于幅度和相位预测。我们发现两个流应该相互通信,这对于相位预测至关重要。此外,我们提出了频率变换块来捕捉沿频率轴的长程相关性。可视化显示,学习到的变换矩阵自发地捕获了谐波相关性,这已被证明有助于 T-F 谱图重建。通过这两项创新,PHASEN 获得了处理详细相位模式和利用谐波模式的能力,在 AVSpeech + AudioSet 数据集上获得 1.76dB SDR 改进。它还在此数据集上取得了优于 Google 网络的显着收益。在 Voice Bank + DEMAND 数据集上,PHASEN 在四个指标上大大优于以前的方法。
57. Review on Mathematical and Mechanical Models of the Vocal Cord
- 阅读时间:2022.2.16
- journal 2012
- 声带振动模型
56. Power-Normalized Cepstral Coefficients (PNCC) for Robust Speech Recognition
- 阅读时间:2022.2.16
- 语音信号特征提取算法
-
IEEE/ACM Transactions on Audio, Speech and Language Processing 2016
- 摘要: 本文提出了一种新的特征提取算法,称为功率归一化倒谱系数 (PNCC),该算法受听觉处理的启发。 PNCC 处理的主要新特性包括使用幂律非线性来替代 MFCC 系数中使用的传统对数非线性、基于非对称滤波的噪声抑制算法来抑制背景激励,以及实现时间掩蔽的模块。我们还建议使用中等时间功率分析,其中环境参数的估计持续时间比通常用于语音的时间长,以及频率平滑。实验结果表明,在存在各种类型的加性噪声和混响环境的情况下,与 MFCC 和 PLP 处理相比,PNCC 处理显着提高了语音的识别精度,计算成本仅比传统的 MFCC 处理略高,并且不会降低识别性能使用干净的语音进行训练和测试时观察到的准确性。与矢量泰勒级数 (VTS) 和 ETSI 高级前端 (AFE) 等技术相比,PNCC 处理在嘈杂环境中还提供更好的识别精度,同时需要的计算量要少得多。我们描述了一种使用“在线处理”的 PNCC 实现,它不需要未来的输入知识。
55. Lips Don’t Lie: A Generalisable and Robust Approach to Face Forgery Detection
- 阅读时间:2022.2.16
- CVPR 2021
-
嘴唇不会说谎(根据嘴巴运动检测假视频)
-
摘要: 尽管当前基于深度学习的面部伪造检测器在受限场景中取得了令人印象深刻的性能,但它们容易受到由看不见的操作方法创建的样本的影响。最近的一些工作显示了泛化方面的改进,但依赖于容易被常见的后处理操作(如压缩)破坏的线索。在本文中,提出了LipForensics,这是一种检测方法,既可以推广到新的操作,又可以承受各种失真。LipForensics的目标是嘴部运动中的高级语义不规则性,这在许多生成的视频中很常见。它包括首先预训练一个时空网络来执行视觉语音识别(唇读),从而学习与自然嘴巴运动相关的丰富内部表征。随后在真实和伪造数据的固定嘴巴嵌入上对时间网络进行微调,以便根据嘴巴运动检测假视频,而不会过度拟合低级、特定于操作的人工制品。大量实验表明,这种简单的方法在对未知操作的泛化和对扰动的鲁棒性方面显着超越了最先进的方法,并阐明了影响其性能的因素。
- Lipreading pretraining. The model is pretrained on Lipreading in the Wild (LRW), a dataset containing over 500,000 utterances spanning hundreds of speakers in various poses. It is trained using the approach proposed in paper: Towards practical lipreading with distilled and efficient models, which employs born-again distillation paper: Born Again Neural Networks. We use the student classifier in the third generation of teacherstudent training. Unless stated otherwise, we use the publicly available, pretrained model found here
54. LipSync3D: Data-Efficient Learning of Personalized 3D Talking Faces from Video using Pose and Lighting Normalization
LipSync3D:使用姿势和光照归一化从视频中进行个性化 3D 说话人脸的数据高效学习
- 阅读时间:2022.2.16
- CVPR 2021
- Lip2Wav
- -Reference :
@INPROCEEDINGS{9577593, author={Lahiri, Avisek and Kwatra, Vivek and Frueh, Christian and Lewis, John and Bregler, Chris}, booktitle={2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, title={LipSync3D: Data-Efficient Learning of Personalized 3D Talking Faces from Video using Pose and Lighting Normalization}, year={2021}, volume={}, number={}, pages={2754-2763}, doi={10.1109/CVPR46437.2021.00278}} - 专注于在不受约束的大词汇量设置中为单个说话者学习准确的嘴唇序列到语音映射。为此,我们收集并发布了一个大规模的基准数据集,这是同类中的第一个,专门用于在自然环境中训练和评估单人口语任务。首次提出了一种具有关键设计选择的新颖方法,以在这种不受约束的情况下实现准确、自然的口型到语音合成。
53. Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
- 阅读时间:2022.2.16
- CVPR2020
- paper: https://ieeexplore.ieee.org/document/9156430
- 学习个人口语风格以实现准确的唇语合成, Words合成, Reference
- TCD-TIMIT Dataset 31.26%(WER)
-
GRID Dataset 14.08%(WER)
@INPROCEEDINGS{9156430, author={Prajwal, K R and Mukhopadhyay, Rudrabha and Namboodiri, Vinay P. and Jawahar, C.V.}, booktitle={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, title={Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis}, year={2020}, volume={}, number={}, pages={13793-13802}, doi={10.1109/CVPR42600.2020.01381}} - 摘要: 当语音不存在或被外部噪音干扰时,人类会不由自主地倾向于从唇部运动中推断出部分对话。在这项工作中,我们探索了唇到语音合成的任务,即,学习仅根据说话者的唇部运动生成自然语音。认识到上下文和特定于说话者的线索对于准确唇读的重要性,我们采取了与现有方法不同的路径。我们专注于在不受约束的大词汇量设置中为单个说话者学习准确的嘴唇序列到语音映射。为此,我们收集并发布了一个大规模的基准数据集,这是同类中的第一个,专门用于在自然环境中训练和评估单人口语任务。我们首次提出了一种具有关键设计选择的新颖方法,以在这种不受约束的情况下实现准确、自然的口型到语音合成。使用定量、定性指标和人工评估的广泛评估表明,我们的方法比该领域以前的工作更易理解四倍。
52. Lip Reading Sentences in the Wild
- 阅读时间:2022.2.16
- CVPR2017
- CNN + LSTM encoder, attentive LSTM decoder
-
唇读
@article{2017, title={Lip Reading Sentences in the Wild}, url={http://dx.doi.org/10.1109/CVPR.2017.367}, DOI={10.1109/cvpr.2017.367}, journal={2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, publisher={IEEE}, author={Chung, Joon Son and Senior, Andrew and Vinyals, Oriol and Zisserman, Andrew}, year={2017}, month={Jul} } - 摘要: 当前最先进的唇读方法基于为自然机器翻译和音频语音识别而设计的序列到序列架构。因此,这些方法没有充分利用嘴唇动力学的特性,导致两个主要缺点。首先,对于从嘴唇图像到视位的映射至关重要的短程时间依赖性没有受到额外的关注。其次,由于使用了全局平均池(GAP),在现有的序列模型中丢弃了局部空间信息。为了很好地解决这些缺点,我们提出了一个时间焦点块来充分描述短程依赖关系和一个时空融合模块(STFM)来保持局部空间信息并减少特征维度。实验结果表明,我们的方法使用更少的训练数据和更轻的卷积特征提取器实现了与最先进的方法相当的性能。由于卷积结构和局部自注意力机制,训练时间减少了 12 天。
51. Spatio-Temporal Fusion Based Convolutional Sequence Learning for Lip Reading
- 阅读时间:2022.2.16
-
ICCV 2019
- 原理:当前最先进的唇读方法基于专为自然机器翻译和音频语音识别而设计的序列到序列架构。这些方法没有充分利用唇部动力学的特性,导致两个主要缺点:
- 对于从唇图像到视位的映射至关重要的短程时间依赖性没有受到额外的关注。
- 由于使用了全局平均池化(GAP),现有序列模型中的局部空间信息被丢弃。
-
本文提出了一个Temporal Focal块来充分描述短程依赖性,并提出一个时空融合模块 (STFM) 来维护局部空间信息并减少特征维度。
- 摘要:
50. Lip Movements Generation at a Glance
- 阅读时间:2022.2.16
-
ECCV 2018
- 摘要: 在本文中,我们考虑以下任务:给定任意音频语音和任意目标身份的嘴唇图像,生成目标身份的合成唇部运动,说出语音。 为了表现良好,模型不仅需要考虑目标身份的保留、合成图像的真实感、唇部图像在序列中的一致性和平滑度,更重要的是,学习音频语音和唇部运动之间的相关性。 为了解决集体问题,我们设计了一个网络来合成嘴唇运动,并提出了一种新的相关损失来同步嘴唇变化和语音变化。 我们的完整模型综合考虑了四个损失; 它经过端到端的训练,对唇形、视角和不同的面部特征具有鲁棒性。 在从实验室记录到野外嘴唇的三个数据集上进行的深思熟虑的实验表明,我们的模型明显优于扩展到此任务的其他最先进的方法。
49. Lipper: Synthesizing thy speech using multi-view lipreading
- 阅读时间:2022.2.16
- AAAI 2019
- 使用多视角camera序列合成语音
- 利用嘴唇图片
-
Phrases 合成 e.g. Excuse me, Goodbye, How are you, Nice to meet you…
-
@misc{https://doi.org/10.48550/arxiv.1907.01367, doi = {10.48550/ARXIV.1907.01367}, url = {https://arxiv.org/abs/1907.01367}, author = {Kumar, Yaman and Jain, Rohit and Salik, Khwaja Mohd. and Shah, Rajiv Ratn and yin, Yifang and Zimmermann, Roger}, keywords = {Audio and Speech Processing (eess.AS), Machine Learning (cs.LG), Sound (cs.SD), Machine Learning (stat.ML), FOS: Electrical engineering, electronic engineering, information engineering, FOS: Electrical engineering, electronic engineering, information engineering, FOS: Computer and information sciences, FOS: Computer and information sciences}, title = {Lipper: Synthesizing Thy Speech using Multi-View Lipreading}, publisher = {arXiv}, year = {2019}, copyright = {Creative Commons Attribution Share Alike 4.0 International}} - 摘要: Lipreading 有很多潜在的应用,例如在监控和视频会议领域。尽管如此,构建唇读系统的大部分工作都仅限于将无声视频分类为表示文本短语的类。然而,将唇读作为基于文本的分类任务存在多个问题,例如它对特定语言和词汇映射的依赖。因此,在本文中,我们提出了一种针对音频系统的多视图唇读,即 Lipper,将其建模为回归任务。该模型将无声视频作为输入,并产生语音作为输出。对于多视图无声视频,我们观察到对单视图语音重建结果的改进。我们通过针对说话人相关、词汇外和说话人无关设置提供一组详尽的实验来证明这一点。此外,我们将 Lipper 的延迟值与其他语音阅读系统进行比较,以显示所产生音频的实时性。我们还对制作的音频进行了用户研究,以了解使用 Lipper 制作的音频的可理解程度。
48. Hearing Lips: Improving Lip Reading by Distilling Speech Recognizers
- 阅读时间:2022.2.16
-
AAAI 2020
- 摘要: 由于深度学习和大规模数据集的可用性,唇读近年来取得了空前的发展。尽管取得了令人鼓舞的结果,但不幸的是,唇读的性能仍然不如其对应的语音识别之一,因为其驱动的模棱两可性质使得从唇动视频中提取判别特征具有挑战性。在本文中,我们提出了一种新方法,称为唇语(LIBS),其目标是通过从语音识别器中学习来加强唇读。我们的方法背后的基本原理是,从语音识别器中提取的特征可以提供互补和判别线索,这些线索很难从嘴唇的细微运动中获得,从而有助于唇读者的训练。具体而言,这是通过从语音识别器向唇读器提取多粒度知识来实现的。为了进行这种跨模态知识蒸馏,我们利用有效的对齐方案来处理音频和视频的长度不一致,以及创新的过滤策略来改进语音识别器的预测。所提出的方法在 CMLR 和 LRS2 数据集上实现了新的最先进的性能,在字符错误率上分别比基线高出 7.66% 和 2.75%。
47. Mutual Information Maximization for Effective Lip Reading
- 阅读时间:2022.2.16
-
arXiv 2020
- 摘要: 近年来,由于深度学习的快速发展及其广泛的潜在应用,唇读引起了越来越多的研究兴趣。唇读任务获得良好性能的一个关键点在很大程度上取决于表示如何有效地捕获唇部运动信息,同时抵抗由姿势、光照条件、说话者外观等变化引起的噪声。为此,我们建议在局部特征级别和全局序列级别引入互信息约束,以增强特征与语音内容的关系。一方面,我们通过施加局部互信息最大化约束 (LMIM) 来约束每个时间步生成的特征,使它们与语音内容具有很强的关系,从而提高模型发现细粒度嘴唇的能力动作和发音相似的单词之间的细粒度差异,例如“花费”和“花费”。另一方面,我们在全局序列级(GMIM)上引入互信息最大化约束,使模型能够更多地关注与语音内容相关的关键帧的判别,而更少地关注语音中出现的各种噪声。过程。通过将这两个优点结合在一起,预计所提出的方法对于有效的唇读具有判别性和鲁棒性。为了验证这种方法,我们对两个大规模基准进行了评估。我们在几个方面进行了详细的分析和比较,包括LMIM和GMIM与基线的比较,学习到的表示的可视化等等。结果不仅证明了所提出方法的有效性,而且还报告了两个基准测试的最新性能。
46. Vid2speech: speech reconstruction from silent video
- 阅读时间:2022.2.16
-
arXiv 2017
- 摘要: 众所周知,语音阅读对于人类来说是一项非常困难的任务。 在本文中,我们提出了一种基于卷积神经网络 (CNN) 的端到端模型,用于从说话人的无声视频帧中生成可理解的声学语音信号。 所提出的 CNN 根据其相邻帧为每个帧生成声音特征。 然后从学习的语音特征中合成波形以产生可理解的语音。 我们表明,通过利用 CNN 的自动特征学习能力,我们可以在 GRID 数据集上获得最先进的单词可理解性,并显示出学习词汇表外 (OOV) 单词的有希望的结果。
45. Towards practical lipreading with distilled and efficient models
- 阅读时间:2022.2.16
-
arXiv 2020
- 摘要: 由于神经网络的复兴,唇读见证了很多进步。最近的工作侧重于通过寻找最佳架构或改进泛化来提高性能等方面。然而,当前的方法与在实际场景中有效部署唇读的要求之间仍然存在显着差距。在这项工作中,我们提出了一系列显着弥合这一差距的创新:首先,我们将 LRW 和 LRW-1000 的最先进性能分别提高到 88.6% 和 46.6%,通过仔细 优化。其次,我们提出了一系列架构变化,包括一个新的深度可分离 TCN 头,它将计算成本削减到(已经非常有效)原始模型的一小部分。第三,我们表明知识蒸馏是恢复轻量级模型性能的非常有效的工具。这导致了一系列具有不同精度-效率权衡的模型。然而,我们最有前途的轻量级模型与当前最先进的模型相当,同时在计算成本和参数数量方面分别减少了 8 倍和 4 倍,我们希望这将能够部署唇读实际应用中的模型。
44. Lip_Reading_Competition
- 阅读时间:2022.2.16
- Project
-
Torch
- 简述:对一组唇语图片序列进行中文单词(词语中只有两字词和四字词)的预测,给定的数据集是封闭集(类别数量是一定的,测试集中的类别均在训练集中出现过), 训练数据数量一共9996个样本,测试数据一共2504个样本,总的类别是313类。通过对数据的分析,且考虑到任务是多分类问题,无需考虑词与词之间的关系,所以将这个问题简单的看作动作视频多分类的问题。
43. 3D Convolutional Neural Networks for Cross Audio-Visual Matching Recognition
- 阅读时间:2022.2.16
- project
- Tensorflow
-
利用唇语图片序列和语音数据进行训练,3D卷积神经网络
- 摘要: 视听识别 (AVR) 已被视为音频损坏时语音识别任务的解决方案,以及用于多说话人场景中说话人验证的视觉识别方法。 AVR 系统的方法是利用从一种模态中提取的信息,通过补充缺失的信息来提高另一种模态的识别能力。本质问题是找到音频和视频流之间的对应关系,这是本文的目标。我们建议使用耦合 3D 卷积神经网络 (3D CNN) 架构,该架构可以将两种模态映射到表示空间中,以使用学习的多模态特征评估视听流的对应关系。所提出的架构将结合空间和时间信息,以有效地找到不同模式的时间信息之间的相关性。通过使用相对较小的网络架构和更小的训练数据集,我们提出的方法超越了现有的类似视听匹配方法的性能,后者使用 3D CNN 进行特征表示。我们还证明了有效的配对选择方法可以显着提高性能。与最先进的方法相比,所提出的方法在相等错误率上实现了超过 20% 的相对改进,在平均精度上实现了超过 7% 的相对改进。
42. Lip reading using CNN and LSTM
- 阅读时间:2022.2.16
- Project
- Runtime: https://github.com/adwin5/CNN-for-visual-speech-recognition (0.51 Validation Accuracy)
- Training: https://github.com/adwin5/lipreading-by-convolutional-neural-network-keras
41. LipNet: End-to-End Sentence-level Lipreading
- 阅读时间:2022.2.16
- arXiv 2016
- Original Repo: https://github.com/bshillingford/LipNet
-
Working Keras Implementation: https://github.com/rizkiarm/LipNet
- 摘要: 唇读是从说话者嘴巴的运动中解码文本的任务。传统方法将问题分为两个阶段:设计或学习视觉特征,以及预测。最近的深度唇读方法是端到端可训练的(Wand et al., 2016; Chung & Zisserman, 2016a)。然而,现有的端到端训练模型的工作只执行单词分类,而不是句子级别的序列预测。研究表明,对于较长的单词,人类的唇读性能会提高 (Easton & Basala, 1982),这表明特征在模棱两可的沟通渠道中捕捉时间上下文的重要性。受此观察的启发,我们提出了 LipNet,这是一种将可变长度的视频帧序列映射到文本的模型,它利用时空卷积、循环网络和连接主义时间分类损失,完全端到端训练。据我们所知,LipNet 是第一个同时学习时空视觉特征和序列模型的端到端句子级唇读模型。在 GRID 语料库上,LipNet 在句子级、重叠说话人分割任务中实现了 95.2% 的准确率,优于经验丰富的人类唇语阅读者和之前 86.4% 的词级最新准确率(Gergen 等人,2016)。
40. Fog Simulation on Real LiDAR Point Clouds for 3D Object Detection in Adverse Weather
- 阅读时间:2022.2.16
-
CVPR 2021
- 摘要:
39. STAR: Simultaneous Tracking and Recognition through Millimeter Waves and Deep Learning
- 阅读时间:2022.2.16
- IEEE 2019
-
毫米波步态检测,DCNN
- 摘要: 步态是人类的自然行走方式,是每个人独特的复杂生物过程。本文旨在利用毫米波(mmWave)提取人体运动的细粒度微多普勒特征,用作用户识别的毫米波步态生物特征。为此,提出了一种深度微多普勒学习系统,该系统利用深度神经网络自动学习和提取毫米波步态生物特征数据中的判别特征,以区分大量人群。特别是,我们的系统由两个子系统组成,包括人体目标跟踪和人体目标识别。跟踪子系统负责检测人类主体的外观,跟踪他/她的位置并估计他/她的步行速度。识别子系统利用跟踪数据生成微多普勒特征作为毫米波生物特征,将其输入定制设计的残差深度卷积神经网络 (DCNN) 以进行自动特征提取。最后,softmax 分类器利用提取的特征进行用户识别。在典型的室内环境中,对 20 人的数据集的 top-1 识别准确率达到 97.45%。
38. Three-Dimensional Millimeter-Wave Imaging for Concealed Weapon Detection
- 阅读时间:2022.2.16
- IEEE
-
利用三维成像实现隐藏武器检测,毫米波成像
- 摘要: 位于华盛顿州里奇兰的太平洋西北国家实验室 (PNNL) 开发了毫米波成像技术和系统,用于检测机场和其他安全地点的隐藏武器和违禁品。这些技术源自微波全息技术,该技术利用在二维孔径上记录的相位和幅度信息来重建目标的聚焦图像。毫米波成像非常适合检测人员携带的隐藏武器或其他违禁品,因为毫米波是非电离的,很容易穿透普通衣服材料,并且会从人体和任何隐藏物品反射回来。本文介绍了一种宽带三维全息微波成像技术。用于机场或其他高通量应用的实用武器检测系统需要大约 3 到 10 秒的高速扫描。为了实现这一目标,已经开发和测试了使用 27-33 GHz 线性顺序切换阵列和高速线性扫描仪的原型成像系统。
37. mTrack: High-Precision Passive Tracking Using Millimeter Wave Radios
- 阅读时间:2022.2.16
- MobiCom 2015
- 60 GHz; Millimeter-wave; Tracking; Phase Shift; Background Cancellation
-
书写跟踪
- 摘要: 基于无线电的被动物体传感可以实现一种新形式的普遍用户-计算机界面。先前的工作采用了各种无线信号特征来在一组预定义的粗略运动模式下感测物体。但操作 UI,如触控板,通常需要识别细粒度的任意运动。本文探讨了以亚厘米精度跟踪被动书写对象(例如钢笔)的可行性。我们通过实用设计 mTrack 来实现这一目标,该设计使用高度定向的 60 GHz 毫米波无线电作为关键支持技术。 mTrack 运行离散光束扫描机制来精确定位对象的初始位置,并使用基于信号相位的模型跟踪其轨迹。此外,mTrack 采用了新颖的机制来抑制背景反射的干扰,利用 60 GHz 信号的短波长。我们制作了 mTrack 原型并在 60 GHz 可重构无线电平台上评估其性能。实验结果表明,mTrack 可以定位/跟踪一支笔的 90% 误差低于 8 毫米,从而实现无线转录和虚拟触控板等新应用。
36. Map-Assisted Millimeter Wave Localization for Accurate Position Location
- 阅读时间:2022.2.16
- arXiv 2019
-
毫米波雷达实现精确定位
- 摘要: 由于大可用带宽允许使用传统空中接口标准进行精确的飞行时间测量,因此可以在毫米波频率进行精确定位。此外,窄天线波束宽度可用于确定基站和移动用户之间的多径分量的到达角和离开角。通过将多路径分量的准确时间和角度信息与环境的 3D 地图(可能由每个用户构建或先验下载)相结合,即使在非视距环境中,也可以实现稳健的定位。在这项工作中,我们为室内办公环境开发了一个精确的 3-D 光线追踪器,并演示了如何将出发角和飞行时间信息与典型大型办公环境的 3-D 地图相融合,从而提供平均精度12.6 cm 的视距和 16.3 cm 的非视距,超过 100 个接收器距离,范围从 1.5 m 到 24.5 m,使用单个基站。我们展示了增加基站数量如何将 21 个位置的平均非视距位置定位精度提高到 5.5 cm,最大传播距离为 24.5 m。
35. Learning to Detect Open Carry and Concealed Object with 77GHz Radar
- 阅读时间:2022.2.16
- arXiv 2021
-
利用77GHz mmWave安检,隐藏在衣服或包中
- 摘要: 检测有害携带物品在智能监控系统中起着关键作用,并具有广泛的应用,例如在机场安检中。在本文中,我们专注于使用低成本 77GHz 毫米波雷达来解决携带物体检测问题的相对未开发的领域。所提出的系统能够实时检测三类物体 - 笔记本电脑、手机和刀 - 在开放式手提箱和隐藏式箱子下,其中物体隐藏在衣服或包中。这种能力是通过用于定位和生成距离-方位角-仰角图像立方体的初始信号处理,然后是基于深度学习的预测网络和用于检测物体的多镜头后处理模块来实现的。已经使用自建的雷达相机测试平台和数据集进行了广泛的实验,以验证系统在检测开放式携带和隐藏物体方面的性能。此外,分析了不同输入、因素和参数对系统性能的影响,提供了对系统的直观理解。该系统将成为未来其他旨在使用 77GHz 雷达检测携带物体的工作的第一个基线。
34. CubeLearn: End-to-end Learning for Human Motion Recognition from Raw mmWave Radar Signals
- 阅读时间:2022.2.16
- arXiv 2021
-
毫米波雷达处理流程中的预处理部分
- 摘要: 近年来,毫米波 FMCW 雷达在以人为中心的应用中引起了巨大的研究兴趣,例如人体手势/活动识别。大多数现有管道都建立在传统的离散傅里叶变换 (DFT) 预处理和深度神经网络分类器混合方法之上,之前的大部分工作都集中在设计下游分类器以提高整体准确度。在这项工作中,我们退后一步,看看预处理模块。为了避免传统 DFT 预处理的缺点,我们提出了一个名为 CubeLearn 的可学习预处理模块,用于直接从原始雷达信号中提取特征,并为 mmWave FMCW 雷达运动识别应用构建端到端深度神经网络。大量实验表明,我们的 CubeLearn 模块持续提高了不同管道的分类准确度,特别是有利于那些以前较弱的模型。我们提供了对所提出模块的初始化方法和结构的消融研究,以及对 PC 和边缘设备上的运行时间的评估。这项工作还可以比较不同的数据立方体切片方法。通过我们的任务不可知设计,我们提出了针对雷达识别问题的通用端到端解决方案的第一步。
33. Manifold Optimization Methods for Hybrid beamforming in mmWave Dual-Function Radar-Communication System
- 阅读时间:2022.2.16
- arXiv 2021
-
混合模拟和数字波束成形架构
- 摘要: 作为一种具有成本效益的替代方案,混合模拟和数字波束成形架构是毫米波 (mmWave) 系统的一种有前途的方案。本文考虑了两种混合波束成形架构,即部分连接和全连接结构,用于毫米波双功能雷达通信(DFRC)系统,其中发射器与下行链路用户通信并同时检测雷达目标。优化问题是通过最小化雷达和通信性能的加权和来制定的,受恒定模量和功率约束。为了解决由这两个问题引起的非凸性,提出了有效的黎曼优化算法。具体而言,针对全连接结构,开发了一种基于乘法器交替方向法(ADMM)的流形算法。而对于部分连接的结构,提出了一种低复杂度的黎曼乘积流形信任域(RPM-TR)算法来逼近近似可选的解决方案。提供了数值模拟来证明所提出方法的有效性。
32. Cross-modal Knowledge Distillation for Vision-to-Sensor Action Recognition
- 阅读时间:2022.2.16
- arXiv 2021
-
标题:用于视觉到传感器动作识别的跨模态知识提取
- 摘要: 最近,基于多模态方法的人类活动识别(HAR)被证明可以提高HAR的准确性和性能。然而,与可穿戴设备(如smartwatch)相关的有限计算资源无法直接支持此类高级方法。为了解决这个问题,本研究引入了一个端到端的传感器知识提取(VSKD)框架。在该VSKD框架中,测试阶段仅需要可穿戴设备的时间序列数据,即加速度计数据。因此,该框架不仅可以减少对边缘设备的计算需求,还可以生成与计算昂贵的多模式方法的性能密切匹配的学习模型。为了保持局部时间关系和便于视觉深度学习模型,我们首先采用基于格拉米安角场(GAF)的编码方法将时间序列数据转换为二维图像。在本研究中,我们分别采用了ResNet18和多尺度TRN(以BN为起始点)作为教师和学生网络。提出了一种新的损失函数,称为距离和角度语义知识损失(DASK),用于缓解视觉和传感器域之间的模态变化。在UTD-MHAD、MMAct和Berkeley MHAD数据集上的大量实验结果证明了所提出的可部署在可穿戴传感器上的VSKD模型的有效性和竞争力。
31. LMR-CBT: Learning Modality-fused Representations with CB-Transformer for Multimodal Emotion Recognition from Unaligned Multimodal Sequences
- 阅读时间:2022.2.16
- arXiv 2021
-
标题:LMR-CBT:基于CB-Transform的学习模态融合表示法在未对齐多模态序列中的多模态情感识别
- 摘要: 学习模态融合表征和处理未对齐的多模态序列在多模态情感识别中具有重要意义和挑战性。现有的方法使用定向两两注意或信息中心来融合语言、视觉和音频模式。然而,这些方法在融合特征时引入了信息冗余,并且在不考虑模式互补性的情况下效率低下。在本文中,我们提出了一种有效的神经网络学习模式融合表示与CBTransformer(LMR-CBT)的多模态情感识别从未对齐的多模态序列。具体来说,我们首先分别对这三种模式进行特征提取,以获得序列的局部结构。然后,我们设计了一种新的跨模态块变换器(CB-transformer),该变换器支持不同模态的互补学习,主要分为局部时间学习、跨模态特征融合和全局自我注意表征。此外,我们将融合后的特征与原始特征拼接,对序列中的情感进行分类。最后,我们在三个具有挑战性的数据集(IEMOCAP、CMU-MOSI和CMU-MOSEI)上进行单词对齐和非对齐实验。实验结果表明,在这两种情况下,我们提出的方法都具有优越性和有效性。与主流方法相比,我们的方法以最少的参数数量达到了最先进的水平。
28. A Hybrid mmWave and Camera System for Long-Range Depth Imaging(arXiv)
- 阅读时间:2022.2.16
-
arXiv 2021
- 摘要: 毫米波雷达因其在毫米波无线电频率下的高带宽而提供出色的深度分辨率。然而,它们本质上存在角分辨率差的问题,这比相机系统差一个数量级,因此孤立地不是一个有能力的 3-D 成像解决方案。我们提出了 Metamoran,该系统结合了雷达和相机系统的互补优势,可在几十米的距离内以高精度获取高方位分辨率的深度图像,所有这些都来自一个固定的有利位置。 Metamoran 可在户外实现丰富的远程深度成像,可应用于路边安全基础设施、监视和广域测绘。我们的主要见解是使用来自使用计算机视觉技术(包括图像分割和单目深度估计)的相机的高方位分辨率来获取对象形状,并将其用作我们新颖的镜面波束成形算法的先验。我们还设计了这种算法,以在反射较弱的杂乱环境和部分遮挡的场景中工作。我们在美国主要城市的 200 个不同场景中对 Metamoran 的深度成像和传感能力进行了详细评估。我们的评估表明,Metamoran 估计的物体深度可达 60~m,中值误差为 28~cm,与普通雷达 + 相机基线相比提高了 13 倍,与单目深度估计相比提高了 23 倍。
27. MmWave Communication With Active Ambient Perception
- 阅读时间:2022.2.16
-
arXiv 2019
- 摘要: 在现有的通信系统中,每个用户设备(UE)的信道状态信息在其移动到新的位置或当另一个UE接替其位置时需要重复估计。底层环境信息,包括潜在反射器的具体布局,提供了有关所有 UE 信道结构的更详细信息,尚未得到充分探索和利用。在本文中,我们以一种新的、间接的方式重新思考毫米波信道估计问题,即,不是每次估计合成信道响应,而是针对任何特定位置,我们首先利用迷人的雷达进行环境感知毫米波天线阵列的能力,然后完成基于位置的稀疏信道重建。这样,准静态UE到达特定位置的稀疏信道可以根据感知到的环境信息快速合成,从而大大降低信令开销和在线计算复杂度。基于重构的毫米波信道,设计并评估了单波束毫米波通信,性能优异。这种方法实际上将雷达与通信集成在一起,这可能为未来的通信系统设计开辟新的范式。
26. Toward Millimeter Wave Joint Radar-Communications: A Signal Processing Perspective
- 阅读时间:2022.2.16
-
arXiv 2019
- 摘要: 具有公共频谱和硬件资源的通信和雷达系统的协同设计预示着一个有效利用有限射频频谱的新时代。这种联合雷达通信(JRC)模型具有成本低、尺寸紧凑、功耗低、频谱共享、性能提高以及信息共享增强的安全性等优点。今天,毫米波 (mm-wave) 通信已成为短距离无线链路的首选技术,因为它们提供了几千兆赫兹宽的传输带宽。该频段也有希望用于短距离雷达应用,这得益于大发射信号带宽带来的高距离分辨率。信号处理技术对于毫米波 JRC 系统的实施至关重要。主要挑战是联合波形设计和性能标准,这将在通信和雷达功能之间进行最佳权衡。由于毫米波 JRC 系统采用大型天线阵列,因此需要新颖的多输入多输出 (MIMO) 信号处理技术。有机会利用认知、压缩感知和机器学习方面的最新进展来减少所需资源并以低开销动态分配它们。本文提供了毫米波 JRC 系统的信号处理视角,重点是波形设计。
25. Milli-RIO: Ego-Motion Estimation with Low-Cost Millimetre-Wave Radar(IEEE)
- 阅读时间:2022.2.16
-
arXiv/IEEE 2019
- 摘要: 由于室内环境中对基于位置的服务的需求快速增长,稳健的室内自我运动估计在过去几十年中引起了人们的极大兴趣。在各种解决方案中,毫米波(MMWave)频谱的调频连续波(FMCW)雷达传感器因其穿透能力强、精度高等固有优势而越来越受到重视。单芯片低成本毫米波雷达作为一种新兴技术,为稳健的自我运动估计提供了一种替代和补充解决方案,由于低功耗和易于系统集成,使其在资源受限的平台中变得可行。在本文中,我们介绍了 Milli-RIO,这是一种基于 MMWave 雷达的解决方案,它利用单芯片低成本雷达和惯性测量单元传感器来估计移动雷达的六自由度自运动。详细的定量和定性评估证明,所提出的方法在室内定位任务中达到了几厘米的精度。
24. Multiple Patients Behavior Detection in Real-time using mmWave Radar and Deep CNNs
- 阅读时间:2022.2.16
-
arXiv 2019
- 摘要: 为了解决医院患者监测中发现的潜在差距,提出了一种使用毫米波雷达和深度卷积神经网络 (CNN) 的新型患者行为检测系统,该系统支持实时同时识别多个患者的行为。在这项研究中,我们使用毫米波雷达跟踪多个患者并检测每个患者的散射点云。对于每个患者,收集一段时间内点云的多普勒模式作为行为特征。创建了一个三层 CNN 模型来对每个患者的行为进行分类。跟踪和点云检测算法也在具有嵌入式图形处理单元 (GPU) 板的毫米波雷达硬件平台上实现,以收集多普勒模式并运行 CNN 模型。在很长一段时间内收集了六种行为的训练数据集,以使用 Adam 优化器训练模型,目标是最小化交叉熵损失函数。最后,该系统进行了实时操作测试,并在预测两个患者场景中每个患者的行为时获得了非常好的推理精度。
23. Passive Radar at the Roadside Unit to Configure Millimeter Wave Vehicle-to-Infrastructure Links
- 阅读时间:2022.2.16
-
IEEE
- 摘要: 毫米波(mmWave)车载信道具有高度动态性,通信链路需要频繁重新配置。在这项工作中,我们建议在路边单元使用无源雷达接收器来减少建立毫米波通信链路的训练开销。具体来说,无源雷达将利用道路上车辆的汽车雷达的传输。接收到的雷达信号的空间协方差将被估计并用于建立通信链路。我们提出了一种不需要发射波形作为参考的简化雷达接收器。为了利用雷达信息进行波束成形,雷达方位功率谱 (APS) 和通信 APS 应该相似。我们概述了一种雷达协方差校正策略,以增加雷达和通信 APS 之间的相似性。我们还提出了一个度量来比较雷达和通信 APS 的相似性,这与可实现的速率有关。我们展示了基于光线追踪数据的模拟结果。结果表明:(i) 协方差校正提高了雷达和通信 APS 的相似性,(ii) 雷达辅助策略显着降低了训练开销,在非视距场景中特别有用。
22. JCR70: A Low-Complexity Millimeter-Wave Proof-of-Concept Platform for a Fully-Digital SIMO Joint Communication-Radar
- 阅读时间:2022.2.16
-
IEEE
- 摘要: 具有毫米波 (mmWave) 频段单输入多输出 (SIMO) 架构的全数字宽带联合通信雷达 (JCR) 将通过增强的设计灵活性实现高联合通信和雷达性能。带有几位模数转换器 (ADC) 的量化接收器将使实用的 JCR 解决方案能够降低未来便携式设备和自动驾驶汽车的功耗。在本文中,我们提出了一个名为 JCR70 的联合通信雷达概念验证平台,以使用 71-76 GHz 频带中的真实信道测量来评估和演示这些 JCR 系统的性能。我们通过使用额外的全双工雷达接收器扩展毫米波通信设置并使用滑轨上的移动天线捕获 SIMO JCR 通道来开发该平台。为了表征我们开发的测试台的 JCR 性能,我们进行了几次室内和室外实验,并对测量数据应用传统和先进的处理算法。实验结果表明,对于高达 5 dB 的信噪比,具有 2-4 b ADC 的量化接收器的性能通常与高分辨率 ADC 非常接近。此外,我们将 JCR70 平台的性能与 INRAS Radarbook 进行了比较,后者是 77 GHz 下最先进的汽车雷达评估平台。
21. Adaptive and Fast Combined Waveform-Beamforming Design for mmWave Automotive Joint Communication-Radar
- 阅读时间:2022.2.16
-
IEEE 2020
- 摘要: 毫米波 (mmWave) 联合通信雷达 (JCR) 将为自动驾驶等应用提供高数据速率通信和高分辨率雷达传感。然而,基于毫米波通信硬件的先前 JCR 系统由于采用了定向通信波束而受到有限的角视场和低雷达估计精度的影响。在本文中,我们为毫米波汽车 JCR 提出了一种自适应且快速的组合波形波束成形设计,其相控阵架构允许在通信和雷达性能之间进行权衡。为了在具有宽视场的多普勒角域中快速估计毫米波汽车雷达信道,我们的 JCR 设计采用发射波束成形器的循环位移来获取雷达信道测量值,并在时空维度。在我们问题中的时空采样约束下,我们优化这些循环移位以最小化 CS 矩阵的相干性。我们使用用于雷达估计的归一化均方误差 (MSE) 度量和用于数据通信的失真 MSE 度量来评估 JCR 性能权衡,这类似于率失真理论中的失真度量。此外,我们为自适应 JCR 组合波形波束成形设计开发了一个基于 MSE 的加权平均优化问题。数值结果表明,我们提出的 JCR 设计能够以低归一化 MSE 来估计多普勒角域中的短程和中程雷达信道,但代价是通信失真 MSE 的小幅退化。
20. Single Channel mmWave FMCW Radar for 2D Target Localization
- 阅读时间:2022.2.16
-
IEEE
- 摘要: 在本文中,我们提出了一种使用两种低成本紧凑型毫米波频率调制连续波 (MMW-FMCW) 雷达的二维目标定位方法。 为了创建 2D 地图,我们利用双边方法,然后是多目标跟踪块来去除重影目标。 最后,我们根据从工作在 79 GHz 的两个 FMCW 雷达收集的数据展示了实验结果。
19. 3D Near-Field Millimeter-Wave Synthetic Aperture Radar Imaging
- 阅读时间:2022.2.16
-
arxiv 2020
- 摘要: 在本文中,我们通过综合创建大孔径效应,在毫米波 (mmWave) 频率下呈现 3D 高分辨率雷达成像过程。 我们使用运行在 79 GHz 的低成本全集成调频连续波 (FMCW) 雷达,然后在近场区域进行合成孔径雷达 (SAR) 成像。最后,我们进行了实际实验并展示了重建图像
18. 3D Motion Capture of an Unmodified Drone with Single-chip Millimeter Wave Radar
- 阅读时间:2022.2.16
-
IEEE
- 摘要: 以 3D 形式准确捕捉空中机器人是在仓库或工厂等室内环境中实现自主操作的关键推动因素,并推动了这些领域的研究。目前最常用的解决方案是光学运动捕捉(例如 VICON)和超宽带(UWB),但由于它们需要在跟踪区域周围间隔开多个摄像头/锚点,因此它们的部署成本高且繁琐。他们还要求改装无人机以携带主动或被动标记。在这项工作中,我们提出了一种可以快速安装的廉价系统,基于单芯片毫米波 (mmWave) 雷达。重要的是,无人机不需要改装或配备任何标记,因为我们利用了来自旋转螺旋桨的多普勒信号。此外,可以从单点进行 3D 跟踪,大大简化了部署。我们开发了一种新颖的深度神经网络,并在 10Hz 下展示了分米级 3D 跟踪,实现了比经典基线更好的性能。我们希望这个低成本系统能够促进廉价的无人机研究和提高自主性。
17. HODET: Hybrid Object DEtection and Tracking using mmWave Radar and Visual Sensors
- 阅读时间:2022.2.16
-
arxiv 2020
- 摘要: 图像传感器已在汽车应用中进行了大量探索,用于避免碰撞和不同程度的自主性。它需要一定程度的亮度,因此,在夜间操作或黑暗条件下使用图像传感器可能会遇到困难的天气,例如雾。雷达传感器已被用于帮助应对可见光谱相机的各种环境挑战。边缘计算技术有可能解决许多问题,例如实时处理要求、从拥挤的服务器卸载处理以及尺寸、重量、功率和成本 (SWaP-C) 限制。本文提出了一种在边缘使用毫米波雷达和视觉传感器的新型混合目标检测和跟踪 (HODET)。 HODET 是一种低 SWaP-C 电子设备的计算应用程序,可在同时使用图像和雷达传感器的情况下执行对象检测、跟踪和识别算法。虽然机器视觉相机本身就可以估计物体的距离,但雷达传感器将提供准确的距离和运动矢量。可以利用这种额外的数据准确性来进一步区分检测到的对象,以防止欺骗攻击。选择真实世界的智能社区公共安全监控场景来验证HODET的有效性,它检测、跟踪感兴趣的对象并识别可疑活动。实验结果证明了该方法的可行性。
16. milliEgo: Single-chip mmWave Radar Aided Egomotion Estimation via Deep Sensor Fusion
- 阅读时间:2022.2.16
- Sensys’2021
- 2021-4-22 组会
-
机器人轨迹估计
-
摘要: 对人和机器人等移动代理的稳健且准确的轨迹估计是为增强现实或自主交互等新兴功能提供空间感知的关键要求。尽管目前由光学技术(例如视觉惯性里程计)主导,但它们仍面临场景照明或无特征表面的挑战。作为替代方案,我们提出了milliEgo,这是一种利用低成本毫米波雷达功能进行鲁棒自我运动估计的新型深度学习方法。尽管毫米波雷达比单目相机具有基本的优势,即提供绝对尺度或深度,但当前的单芯片解决方案具有有限且稀疏的成像分辨率,这使得现有的点云配准技术变得脆弱。我们提出了一种新架构,该架构针对解决这一具有挑战性的姿势转换问题进行了优化。其次,将毫米波姿态估计与额外的传感器(例如)稳健地融合在一起。惯性或视觉传感器,我们引入了深度融合的混合注意力方法。通过大量实验,我们证明了我们提出的系统能够实现 1.3% 的 3D 误差漂移,并且可以很好地推广到看不见的环境。我们还表明,神经架构可以变得高效并适用于实时嵌入式应用程序。
@inbook{10.1145/3384419.3430776, author = {Lu, Chris Xiaoxuan and Saputra, Muhamad Risqi U. and Zhao, Peijun and Almalioglu, Yasin and de Gusmao, Pedro P. B. and Chen, Changhao and Sun, Ke and Trigoni, Niki and Markham, Andrew}, title = {MilliEgo: Single-Chip MmWave Radar Aided Egomotion Estimation via Deep Sensor Fusion}, year = {2020}, isbn = {9781450375900}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3384419.3430776}, booktitle = {Proceedings of the 18th Conference on Embedded Networked Sensor Systems}, pages = {109–122}, numpages = {14}}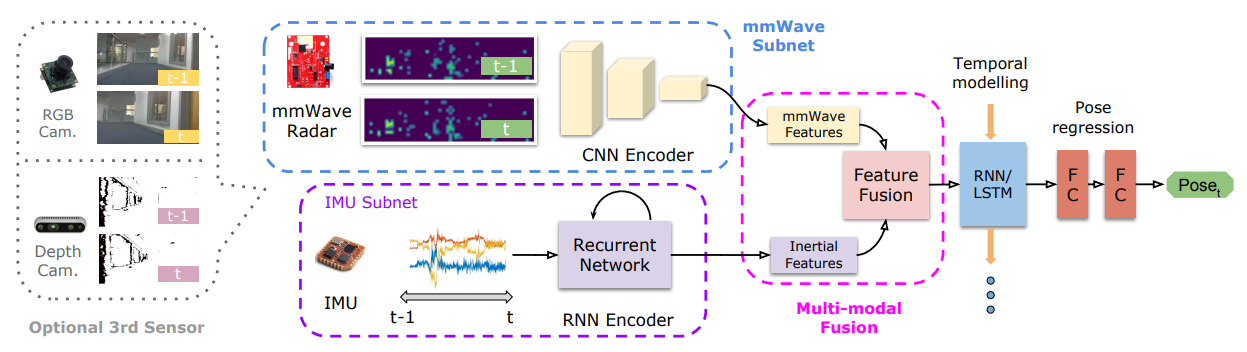
15. Face Verification Using 60 GHz 802.11 waveforms
- 阅读时间:2022.2.16
- arXiv 2020
-
毫米波 + 人脸验证
-
摘要: 研究了基于毫米波中人脸雷达特征的身份验证。 使用 802.11 Qualcomm ad/y 网络的芯片组,它是在雷达模式下运行的电缆。 收集了一个包含 200 个不同人脸的数据集用于测试。 我们的初步研究显示了将自动编码器应用于手头设置的有希望的结果。
@misc{https://doi.org/10.48550/arxiv.2002.11965, doi = {10.48550/ARXIV.2002.11965}, url = {https://arxiv.org/abs/2002.11965}, author = {Hof, Eran and Sanderovich, Amichai and Hemo, Evyatar}, keywords = {Signal Processing (eess.SP), Computer Vision and Pattern Recognition (cs.CV), FOS: Electrical engineering, electronic engineering, information engineering, FOS: Electrical engineering, electronic engineering, information engineering, FOS: Computer and information sciences, FOS: Computer and information sciences}, title = {Face Verification Using 60~GHz 802.11 waveforms}, publisher = {arXiv}, year = {2020}, copyright = {arXiv.org perpetual, non-exclusive license}}
14. Long-Range Gesture Recognition Using Millimeter Wave Radar
- 阅读时间:2022.2.16
- arXiv 2020
-
毫米波实现手势识别
-
摘要: 基于毫米波 (mmWave) 的手势识别技术提供了良好的人机交互 (HCI) 体验。 先前的工作专注于近距离手势识别,但在范围扩展方面存在不足,即他们无法识别距离相当大的噪声运动超过一米的手势。 在本文中,我们设计了一个远程手势识别模型,该模型利用了一种新颖的数据处理方法和一个定制的人工卷积神经网络 (CNN)。 首先,我们将手势分解为多个反射点,并提取其描绘手势细节的时空特征。 其次,我们设计了一个CNN来分别学习提取特征的变化模式并输出识别结果。 我们通过在商用毫米波雷达上实施来彻底评估我们提出的系统。 此外,我们还提供了更广泛的评估,以证明所提出的系统在几个现实场景中是实用的。
@InProceedings{10.1007/978-3-030-64243-3_3, author="Liu, Yu and Wang, Yuheng and Liu, Haipeng and Zhou, Anfu and Liu, Jianhua and Yang, Ning", editor="Yu, Zhiwen and Becker, Christian and Xing, Guoliang", title="Long-Range Gesture Recognition Using Millimeter Wave Radar", booktitle="Green, Pervasive, and Cloud Computing", year="2020", publisher="Springer International Publishing", address="Cham", pages="30--44", isbn="978-3-030-64243-3" }
13. mm-Pose: Real-Time Human Skeletal Posture Estimation using mmWave Radars and CNNs
- 阅读时间:2022.2.16
- arXiv 2019
-
毫米波骨骼关键点检测
-
摘要: 在本文中,提出了一种使用毫米波雷达实时检测和跟踪人体骨骼的新方法 mm-Pose。据作者所知,这是第一种使用毫米波雷达反射信号检测 > 15 个不同骨骼关节的方法。所提出的方法将在交通监控系统、自动驾驶汽车、患者监控系统和国防军中找到多种应用,以实时检测和跟踪人体骨骼,以进行有效和预防性的决策。雷达的使用使系统能够在场景照明和恶劣天气条件下运行稳健。距离、方位角和仰角的反射雷达点云首先在距离-方位角和距离-仰角平面上解析和投影。还提出了一种新颖的小尺寸高分辨率雷达图像表示,它克服了传统点云数据的稀疏性,并显着减少了后续的机器学习架构。 RGB 通道被分配了距离、仰角/方位角的归一化值以及每个点的反射信号的功率电平。分叉的 CNN 架构用于使用雷达到图像的表示来预测 3D 空间中骨骼关节的真实位置。所提出的方法针对四种主要运动的单个人类场景进行了测试,(i) 步行,(ii) 摆动左臂,(iii) 摆动右臂,以及 (iv) 摆动双臂,以验证对范围内运动的准确预测,方位角和仰角。介绍了详细的方法、实施、挑战和验证结果。
- Reference:
@ARTICLE{9083948, author={Sengupta, Arindam and Jin, Feng and Zhang, Renyuan and Cao, Siyang}, journal={IEEE Sensors Journal}, title={mm-Pose: Real-Time Human Skeletal Posture Estimation Using mmWave Radars and CNNs}, year={2020}, volume={20}, number={17}, pages={10032-10044}, doi={10.1109/JSEN.2020.2991741}}
12. Realizing Multi-Point Vehicular Positioning via Millimeter-wave Transmission
- 阅读时间:2022.2.16
-
arXiv 2019
-
摘要: 全尺度环境的多点检测是自动驾驶中的一个重要问题。最先进的定位技术(如RADAR和LIDAR)无法在没有视线的情况下进行实时检测。为了解决这个问题,本文提出了一种通过毫米波(mmWave)传输的新型多点车辆定位技术,该技术利用了从目标车辆(TV)到的多径反射传感车辆(SV),使SV能够在多径反射的帮助下快速捕获非视线(NLoS)中电视的形状和位置信息。一种基于到达相位差(PDoA)的双曲线定位算法被设计来实现TV和SV之间的同步。 stepped-frequency-continuous-wave (SFCW) 用作电视多点检测的信号。与传统定位技术相比,收发器分离使我们的方法能够在 NLoS 条件下工作并实现更低的延迟。
- Reference:
@article{DBLP:journals/corr/abs-1904-13010, author = {Zezhong Zhang and Seung{-}Woo Ko and Rui Wang and Kaibin Huang}, title = {Realizing Multi-Point Vehicular Positioning via Millimeter-wave Transmission}, journal = {CoRR}, volume = {abs/1904.13010}, year = {2019}, url = {http://arxiv.org/abs/1904.13010}, eprinttype = {arXiv}, eprint = {1904.13010}, timestamp = {Fri, 24 Jul 2020 17:11:15 +0200}, biburl = {https://dblp.org/rec/journals/corr/abs-1904-13010.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}}
11. Cross-Modal Contrastive Learning of Representations for Navigation using Lightweight, Low-Cost
- 阅读时间:2022.2.16
- IEEE 2021
-
摘要: Deep reinforcement learning (RL) 已成功应用于各种任务。为了学习无人驾驶车辆的无碰撞策略,深度强化学习已被用于训练各种类型的数据,例如彩色图像、深度图像和 LiDAR 点云,而不使用经典的地图定位计划方法.然而,现有方法受限于它们对相机和 LiDAR 设备的依赖,这些设备在不利的环境条件下(例如,烟雾缭绕的环境)会降低传感性能。作为回应,我们建议使用重量轻且价格低廉的单芯片毫米波 (mmWave) 雷达进行基于学习的自主导航。然而,由于毫米波雷达信号通常嘈杂且稀疏,我们提出了一种跨模态对比学习表征(CM-CLR)方法,该方法在训练阶段最大化毫米波雷达数据和激光雷达数据之间的一致性。我们在真实世界的机器人中评估了我们的方法,与 1) 使用跨模态生成重建和 RL 策略的具有两个独立网络的方法和 2) 没有跨模态表示的基线 RL 策略相比。我们提出的具有对比学习的端到端深度强化学习策略成功地引导机器人穿过充满烟雾的迷宫环境,并且与产生嘈杂的人工墙或障碍物的生成重建方法相比,取得了更好的性能。所有预训练模型和硬件设置都可以开放访问以重现本研究,并可从 https://arg-nctu.github.io/projects/deeprl-mmWave.html 获得。
- Reference:
@article{DBLP:journals/corr/abs-2101-03525, author = {Jui{-}Te Huang and Chen{-}Lung Lu and Po{-}Kai Chang and Ching{-}I Huang and Chao{-}Chun Hsu and Zu Lin Ewe and Po{-}Jui Huang and Hsueh{-}Cheng Wang}, title = {Cross-Modal Contrastive Learning of Representations for Navigation using Lightweight, Low-Cost Millimeter Wave Radar for Adverse Environmental Conditions}, journal = {CoRR}, volume = {abs/2101.03525}, year = {2021}, url = {https://arxiv.org/abs/2101.03525}, eprinttype = {arXiv}, eprint = {2101.03525}, timestamp = {Thu, 21 Jan 2021 14:42:30 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-2101-03525.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
10. DeepPoint: A Deep Learning Model for 3D Reconstruction in Point Clouds via mmWave Radar
- 阅读时间:2022.2.16
-
arXiv 2021
-
摘要: 最近的研究表明,毫米波雷达传感对于低能见度环境中的物体检测是有效的,这使其成为自动导航系统(如自动驾驶汽车)中的理想技术。然而,由于雷达信号具有稀疏性、低分辨率、镜面反射和高噪声等特点,通过毫米波雷达传感重建3D物体形状仍然具有挑战性。基于我们最近提出的 3DRIMR(通过毫米波雷达进行 3D 重建和成像),我们在本文中介绍了 DeepPoint,这是一种深度学习模型,它以点云格式生成 3D 对象,其性能明显优于原始 3DRIMR 设计。该模型采用基于条件生成对抗网络 (GAN) 的深度神经网络架构。它以 3DRIMR 的 Stage 1 生成的对象的 2D 深度图像作为输入,并输出对象的平滑和密集的 3D 点云。该模型由一个新颖的生成器网络组成,该网络利用一系列 DeepPoint 块或层来提取从不同角度观察时对象的多个粗糙和稀疏输入点云的联合的基本特征,因为这些输入点云可能包含许多由于 3DRIMR 的 Stage 1 生成过程不完善而导致不正确的点。 DeepPoint 的设计采用深度结构来捕获输入点云的全局特征,它依赖于优化选择的 DeepPoint 块数和跳过连接来实现性能提升。原始的 3DRIMR 设计。我们的实验表明,该模型在重建 3D 对象方面明显优于原始 3DRIMR 和其他标准技术。
- Reference:
@misc{https://doi.org/10.48550/arxiv.2109.09188, doi = {10.48550/ARXIV.2109.09188}, url = {https://arxiv.org/abs/2109.09188}, author = {Sun, Yue and Zhang, Honggang and Huang, Zhuoming and Liu, Benyuan}, title = {DeepPoint: A Deep Learning Model for 3D Reconstruction in Point Clouds via mmWave Radar}, publisher = {arXiv}, year = {2021}, copyright = {arXiv.org perpetual, non-exclusive license}}
9. Hybrid Beamforming With Sub-arrayed MIMO Radar: Enabling Joint Sensing and Communication at mmWave Band
- 阅读时间:2022.2.16
- arXiv 2018
-
beamforming, 波束成形
- 摘要: 在本文中,我们提出了一种用于毫米波 (mmWave) 频段双功能雷达通信 (DFRC) 系统的波束成形设计,其中联合开发了混合波束成形和子阵列 MIMO 雷达技术。我们假设基站 (BS) 正在为位于非视距 (NLoS) 信道中的用户设备 (UE) 提供服务,同时主动检测位于视距 (LoS) 中的多个目标) 渠道。给定最佳通信波束形成器和所需的雷达波束模式,我们建议在非凸恒模 (CM) 和功率约束下设计模拟和数字波束形成器,从而使通信和雷达波束形成误差的加权总和最小化。公式化的优化问题可以分解为三个子问题,并通过交替最小化方法解决。数值模拟验证了所提出的波束成形设计的可行性,并表明我们的方法在传感和通信之间提供了有利的性能折衷。
@INPROCEEDINGS{8683591, author={Liu, Fan and Masouros, Christos}, booktitle={ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Hybrid Beamforming with Sub-arrayed MIMO Radar: Enabling Joint Sensing and Communication at mmWave Band}, year={2019}, volume={}, number={}, pages={7770-7774}, doi={10.1109/ICASSP.2019.8683591}}
8. Meyer Graph Convolutional Networks for 3D Object Detection on Radar Data
- 阅读时间:2022.2.16
-
ICCV 2021
-
摘要: 尽管雷达传感器具有价格低廉、耐候性强、距离远且可额外提供速度信息的优势,但在满足全自动驾驶的要求方面,与激光雷达和摄像头相比,它仍然遥遥无期。 在这项工作中,我们专注于充分利用原始雷达张量数据,而不是建立在传统雷达信号处理技术的典型结果的人为偏见点云上。 在原始雷达张量上使用图神经网络,我们在平均精度上比基于网格的卷积基线网络显着提高了 10%。 两个网络的性能都在具有密集城市交通场景、不同对象方向和距离以及遮挡直至视觉上完全遮挡的对象的真实世界数据集上进行评估。 我们提出的网络将雷达数据上最先进的 3D 目标检测的最大范围从之前的 20m 增加到 100m。
- Reference:
@INPROCEEDINGS{9607427, author={Meyer, Michael and Kuschk, Georg and Tomforde, Sven}, booktitle={2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)}, title={Graph Convolutional Networks for 3D Object Detection on Radar Data}, year={2021}, volume={}, number={}, pages={3053-3062}, doi={10.1109/ICCVW54120.2021.00340}}
7. Method of Measuring Doppler Shift of Moving Targets Using FMCW Maritime Radar
- 阅读时间:2022.2.16
-
IEEE
-
摘要: 在 FMCW(调频连续波)海上雷达工作期间,系统发射连续无线电能量,其频率由三角形或锯齿形信号调制。结果,传输信号的频率随时间逐渐变化。当信号被物体反射时,接收波形将建立传输波形的延迟副本,时间延迟作为目标距离的度量。如果目标正在移动,雷达系统将在接收到的信号中记录多普勒频移。与发射信号的频率相比,接收信号在目标接近时显示出较高的频率,而在目标远离雷达位置时显示出较低的频率。因此,总的多普勒频移可能是源和观察者运动的叠加造成的。具体来说,多普勒频移量与目标的径向速度成正比。在首先执行距离傅立叶变换(距离 FFT)之后可以确定多普勒频移。对于感兴趣的目标,我们可以重复范围 FFT,直到我们有足够的数据来执行第二级 FFT。第二次 FFT 的结果是一个二维复值矩阵,其频谱峰值对应于移动目标的多普勒频移。这种方法称为多普勒 FFT。本文介绍了使用这种方法测量目标速度的一些结果。
- Reference:
@INPROCEEDINGS{6654465, author={Sediono, Wahju}, booktitle={Proceedings of 2013 IEEE International Conference on Teaching, Assessment and Learning for Engineering (TALE)}, title={Method of measuring Doppler shift of moving targets using FMCW maritime radar}, year={2013}, volume={}, number={}, pages={378-381}, doi={10.1109/TALE.2013.6654465}}
6. MIMO-SAR: A Hierarchical High-resolution Imaging Algorithm for mmWave FMCW Radar in Autonomous Driving
- 阅读时间:2022.2.16
- arXiv2021
- 将SAR原理应用于MIMO雷达,汽车辅助驾驶
-
77 GHz FMCW radar chip AWR1843
-
摘要: 毫米波雷达正越来越多地集成到商用车辆中,以支持先进的驾驶辅助系统功能。 由于天线尺寸和位置的形状因数限制,当今车载雷达成像的一个主要缺点是方位分辨率较差(用于侧视操作)。 在本文中,我们通过一种新的多输入多输出合成孔径雷达 (MIMO-SAR) 成像技术提出了一种解决方案,该技术将相干 SAR 原理应用于车载 MIMO 雷达,以提高侧视(角)分辨率。 建议的 2 阶段分层 MIMO-SAR 处理工作流程在保持图像分辨率的同时大大减少了计算负载。 为了在合成孔径上实现相干处理,我们集成了一种雷达里程计算法,用于估计自我雷达的轨迹。 MIMO-SAR 算法通过车载雷达平台采集的仿真和真实实验数据进行验证。
- Reference:
@ARTICLE{9465646, author={Gao, Xiangyu and Roy, Sumit and Xing, Guanbin}, journal={IEEE Transactions on Vehicular Technology}, title={MIMO-SAR: A Hierarchical High-Resolution Imaging Algorithm for mmWave FMCW Radar in Autonomous Driving}, year={2021}, volume={70}, number={8}, pages={7322-7334}, doi={10.1109/TVT.2021.3092355}}
5. mmPose-NLP A Natural Language Processing Approach to Precise Skeletal Pose Estimation using mmWave Radars
- 阅读时间:2022.2.16
- arXiv2021
-
毫米波雷达 + 骨架关节点
-
摘要: 在本文中,我们介绍了 mmPose-NLP,这是一种使用毫米波 (mmWave) 雷达数据的新型自然语言处理 (NLP) 启发式序列到序列 (Seq2Seq) 骨架关键点估计器。据作者所知,这是第一种仅使用毫米波雷达数据精确估计多达 25 个骨架关键点的方法。骨骼姿态估计在自动驾驶汽车、交通监控、患者监控、步态分析、国防安全取证等多种应用中至关重要,并有助于预防性和可操作的决策。与传统使用的光学传感器相比,将毫米波雷达用于此任务具有多项优势,主要是其对场景照明和恶劣天气条件的操作鲁棒性,在这些条件下,光学传感器性能显着下降。毫米波雷达点云 (PCL) 数据首先被体素化(类似于 NLP 中的标记化),体素化雷达数据的 N 帧(类似于 NLP 中的文本段落)受到建议的 mmPose-NLP 架构的影响,其中体素预测 25 个骨架关键点的索引(类似于 NLP 中的关键字提取)。使用标记化过程中使用的体素字典将体素索引转换回现实世界的 3-D 坐标。平均绝对误差 (MAE) 指标用于测量所提出系统相对于地面实况的准确性,所提出的 mmPose-NLP 在深度、水平和垂直轴上提供 <3 cm 的定位误差。对于 N = {1,2,..,10},还研究了输入帧数与性能/精度的影响。本文介绍了综合方法、结果、讨论和局限性。所有源代码和结果都在 GitHub 上提供,用于在这个使用毫米波雷达的关键但新兴的骨架关键点估计领域进一步研究和开发。
- Reference:
@ARTICLE{9723439, author={Sengupta, Arindam and Cao, Siyang}, journal={IEEE Transactions on Neural Networks and Learning Systems}, title={mmPose-NLP: A Natural Language Processing Approach to Precise Skeletal Pose Estimation Using mmWave Radars}, year={2022}, volume={}, number={}, pages={1-12}, doi={10.1109/TNNLS.2022.3151101}}
4. Perception Through 2D-MIMO FMCW Automotive Radar Under Adverse Weather
- 阅读时间:2022.2.16
- arXiv2021
-
TI官网提供的 4芯片FMCW级联,2D MIMO virtual array formed by 12 TX and 16 RX
-
摘要: 毫米波 (mmWave) 雷达越来越多地集成到商用车辆中,以支持新的自适应驾驶辅助系统 (ADAS) 功能,这些功能需要对物体进行准确的定位和多普勒速度估计,而不受环境条件的影响。为了探索基于雷达的 ADAS 应用,我们使用德州仪器 (Texas Instrument) 的 4 芯片级联 FMCW 雷达 (TIDEP-01012) 更新了我们的测试台,该雷达形成了非均匀 2D MIMO 虚拟阵列。在本文中,我们开发了必要的接收信号模型,用于应用不同的到达方向 (DoA) 估计算法,并在受控场景下通过实验验证它们在形成的虚拟阵列上的性能。为了测试毫米波雷达在恶劣天气条件下的稳健性,我们通过一个驱动的车载平台收集了各种物体的原始雷达数据集(解调后的 I-Q 样本),特别是在相机基本上无效的下雪和有雾的情况下。介绍了雷达成像算法对该数据集的初步结果。
- Reference:
@INPROCEEDINGS{9551127, author={Gao, Xiangyu and Roy, Sumit and Xing, Guanbin and Jin, Sian}, booktitle={2021 IEEE International Conference on Autonomous Systems (ICAS)}, title={Perception Through 2D-MIMO FMCW Automotive Radar Under Adverse Weather}, year={2021}, volume={}, number={}, pages={1-5}, doi={10.1109/ICAS49788.2021.9551127}}
3. Performance and Scaling of Collaborative Sensing and Networking for Automated Drivering Application
- 阅读时间:2022.2.16
-
Published in: 2018 IEEE International Conference on Communications Workshops (ICC Workshops)
-
摘要: 自动驾驶系统的一个关键要求是在动态变化的环境中实现态势感知。为此,车辆将配备各种传感器,例如激光雷达、摄像头、(毫米波)雷达等。不幸的是,单个车辆的感测“覆盖范围”和“可靠性”受到环境障碍物的限制,例如其他车辆、建筑物、人、物体等。一种可能的解决方案是在可能由基础设施辅助的车辆之间采用协作感知。本文介绍了车辆协同传感和网络的新模型和性能扩展分析。特别是,覆盖率和可靠性增益是量化的,它们对协作车辆渗透的依赖也是如此。我们还根据 V2V 和/或 V2I 容量要求以及它们如何依赖于渗透来评估相关的通信负载。协作传感被证明可以大大提高传感性能,例如,将覆盖率从 20% 提高到 80%,渗透率为 20%。在渗透受限和可靠性要求更高的场景中,可以使用基础设施来感知环境和中继数据。一旦渗透率足够高,传感车辆就会提供良好的覆盖范围,数据流量可以有效地“卸载”到 V2V 连接,使 V2I 资源可用于支持其他车内服务。
- Reference:
@INPROCEEDINGS{8403778, author={Wang, Yicong and de Veciana, Gustavo and Shimizu, Takayuki and Lu, Hongsheng}, booktitle={2018 IEEE International Conference on Communications Workshops (ICC Workshops)}, title={Performance and Scaling of Collaborative Sensing and Networking for Automated Driving Applications}, year={2018}, volume={}, number={}, pages={1-6}, doi={10.1109/ICCW.2018.8403778}}
2. milliEye: A Lightweight mmWave Radar and Camera Fusion System for Robust Object Detection
- 阅读时间:2022.2.16
- ACM IoTDI ‘2021
- 一种轻量级的毫米波雷达和相机融合系统
- 毫米波点云数据推荐proposals bbox,然后与camera数据融合
-
TI-IWR6843 + Camera
-
摘要: 最近已经提出了广泛的高级深度学习算法用于图像分类和对象检测。然而,这些方法的有效性在许多可见度或照明较差的现实世界场景中会受到显着限制。与 RGB 摄像头相比,毫米波 (mmWave) 雷达不受上述环境变化的影响,可以在不利条件下为摄像头提供帮助。为此,我们提出了milliEye,这是一种轻量级的毫米波雷达和相机融合系统,用于在边缘平台上进行稳健的物体检测。与现有的传感器融合方法相比,milliEye 有几个关键优势。首先,虽然milliEye以基于学习的方式融合了两种传感模式,但它只需要新场景的少量标记图像/雷达数据,因为它可以充分利用大型公共图像数据集进行广泛的训练。这一显着特征使milliEye 能够适应高度复杂的现实世界环境。其次,基于将基于图像的物体检测器与其他模块分离的新颖架构,milliEye 与不同的现成的基于图像的物体检测器兼容。因此,它可以利用物体检测算法的快速进步。此外,由于采用了高计算效率的融合方法,milliEye 是轻量级的,因此适用于基于边缘的实时应用程序。为了评估milliEye的性能,我们收集了一个新的用于物体检测的雷达和相机融合数据集,其中包含普通光和低光照明条件。结果表明,与最先进的基于图像的物体检测器(包括 Tiny YOLOv3 和 SSD)相比,milliEye 可以提供显着的性能提升,尤其是在低光场景中,同时在边缘平台上产生低计算开销。
- Reference:
@inproceedings{10.1145/3450268.3453532, author = {Shuai, Xian and Shen, Yulin and Tang, Yi and Shi, Shuyao and Ji, Luping and Xing, Guoliang}, title = {MilliEye: A Lightweight MmWave Radar and Camera Fusion System for Robust Object Detection}, year = {2021}, isbn = {9781450383547}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3450268.3453532}, doi = {10.1145/3450268.3453532}, booktitle = {Proceedings of the International Conference on Internet-of-Things Design and Implementation}, pages = {145–157}, numpages = {13}, keywords = {mmWave Radar, Sensor Fusion, Object Detection}, location = {Charlottesvle, VA, USA}, series = {IoTDI '21} }
1. Spoofing Attacks Against Vehicular FMCW Radar
- 阅读时间:2022.2.16
- CCS->ASHES’2021
-
汽车FMCW毫米波雷达,自动辅助驾驶(ADAS),mmWave,车辆雷达攻击
-
摘要: 面对网络攻击,车内乘客的安全和保障是汽车行业的一个关键问题,尤其是随着高级驾驶辅助系统 (ADAS) 的出现和自动驾驶汽车 (AV) 的巨大改进。此类平台使用各种传感器,包括摄像头、激光雷达和毫米波雷达。如果被攻击者利用,这些传感器本身可能会带来潜在的安全隐患。在本文中,我们提出了一种攻击汽车 FMCW 毫米波雷达的系统,该雷达使用快速chirp调制。 使用单个雷达,我们的攻击系统能够同时欺骗受害车辆测量的距离和速度,呈现与控制车辆运动的物理定律相一致的幻象测量值。攻击雷达控制延迟以欺骗其距离,并使用相位补偿和控制以欺骗其速度。在开发了攻击理论之后,我们通过使用软件定义无线电构建基于概念验证的基于硬件的系统来演示欺骗攻击。我们成功演示了两种真实世界场景,其中受害雷达被欺骗以检测幻像紧急停止或幻像加速度,同时测量相干范围和速度。我们还讨论了几种可以减轻所描述的攻击的对策。
- Reference:
@inbook{10.1145/3474376.3487283, author = {Komissarov, Rony and Wool, Avishai}, title = {Spoofing Attacks Against Vehicular FMCW Radar}, year = {2021}, isbn = {9781450386623}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3474376.3487283}, booktitle = {Proceedings of the 5th Workshop on Attacks and Solutions in Hardware Security}, pages = {91–97}, numpages = {7}}